

Replication lag
Typically, in our replica sets, we monitoring the replication lag, that is a measure of who far a secondary is behind the primary:
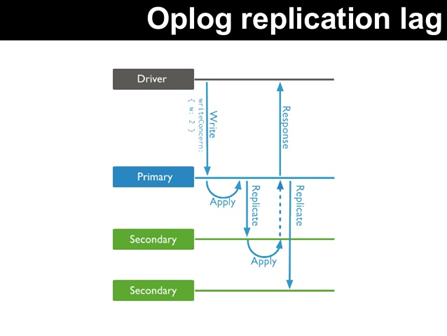

Exist two types of replication:
Chained replication, configured by default. A chained replication occurs when a secondary member replicates from another secondary member instead of from the primary. Recommended for reducing the load of the primary.
Primary replication needs to explicit configure. A primary replication occurs when all secondary members replicate from the primary.
In mongo shell we get the information with rs.printSlaveReplicationInfo()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Output example source: m1.example.net:27017 syncedTo: Thu Apr 10 2014 10:27:47 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Thu Apr 10 2014 10:27:47 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary |
Oplog window
The other important aspect that we need to be in mind, is the Oplog window, is the time difference between the oldest and newest entries in the oplog.
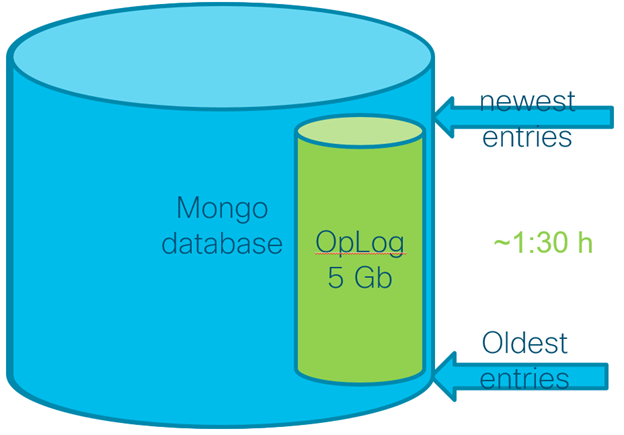

The oplog window tells us the amount of time to work with secondary members, for example:
- Add new secondary member
- Install new OS patch
- Install new MongoDB version
- Full resync of the secondary member
- Recover a secondary member from a failure
For show information of oplog window in mongo shell rs.printReplicationInfo()
|
1 2 3 4 5 6 7 8 9 10 11 |
Output example configured oplog size: 192MB log length start to end: 65422secs (18.17hrs) oplog first event time: Mon Jun 23 2014 17:47:18 GMT-0400 (EDT) oplog last event time: Tue Jun 24 2014 11:57:40 GMT-0400 (EDT) now: Thu Jun 26 2014 14:24:39 GMT-0400 (EDT) |
Conclusion
It´s very important to monitor the health of our replica sets, the aspects to monitor are:
Oplog lag
OplogWindow
We can use monitoring tools like Nagios, Mongo Compass, Atlas, to automating the monitoring and alert if something goes wrong.
![]()
