



There are actually several ways to control disk latency in SQL Server. But in this article, I will be explaining the most frequently used DMV (Dynamic Management View).
Microsoft announced in 2005 that a DMV called sys.dm_io_virtual_file_stats was available. SQL Server records data on execution plans, resource usage, physical and logical uses of indexes since the last boot.
We can get information about the status of the system by querying them. The dm_io_virtual_file_stats function is one of them and returns I/O usage statistics of data and log files of databases.
|
1 2 3 4 |
sys.dm_io_virtual_file_stats ( { database_id | NULL } , { file_id | NULL } ) |
Can elaborate on this DMV using the query below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
SELECT [ReadLatency] = CASE WHEN [num_of_reads] = 0 THEN 0 ELSE ([io_stall_read_ms] / [num_of_reads]) END, [WriteLatency] = CASE WHEN [num_of_writes] = 0 THEN 0 ELSE ([io_stall_write_ms] / [num_of_writes]) END, [Latency] = CASE WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0) THEN 0 ELSE ([io_stall] / ([num_of_reads] + [num_of_writes])) END, [Latency Desc] = CASE WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0) THEN 'N/A' ELSE CASE WHEN ([io_stall] / ([num_of_reads] + [num_of_writes])) < 2 THEN 'Excellent' WHEN ([io_stall] / ([num_of_reads] + [num_of_writes])) < 6 THEN 'Very good' WHEN ([io_stall] / ([num_of_reads] + [num_of_writes])) < 11 THEN 'Good' WHEN ([io_stall] / ([num_of_reads] + [num_of_writes])) < 21 THEN 'Poor' WHEN ([io_stall] / ([num_of_reads] + [num_of_writes])) < 101 THEN 'Bad' WHEN ([io_stall] / ([num_of_reads] + [num_of_writes])) < 501 THEN 'Alas!' ELSE 'Get out!!' END END, [AvgBPerRead] = CASE WHEN [num_of_reads] = 0 THEN 0 ELSE ([num_of_bytes_read] / [num_of_reads]) END, [AvgBPerWrite] = CASE WHEN [num_of_writes] = 0 THEN 0 ELSE ([num_of_bytes_written] / [num_of_writes]) END, [AvgBPerTransfer] = CASE WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0) THEN 0 ELSE (([num_of_bytes_read] + [num_of_bytes_written]) / ([num_of_reads] + [num_of_writes])) END, LEFT ([mf].[physical_name], 2) AS [Drive], DB_NAME ([vfs].[database_id]) AS [DB], [mf].[physical_name] FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS [vfs] JOIN sys.master_files AS [mf] ON [vfs].[database_id] = [mf].[database_id] AND [vfs].[file_id] = [mf].[file_id] --WHERE DB_NAME ([vfs].[database_id])='DBA' -- db name ORDER BY [Latency] DESC -- ORDER BY [ReadLatency] DESC -- ORDER BY [WriteLatency] DESC; GO |
The query output is as follows.


The column named “Latency Desc” will help us to make sense of the query result. Subject to the following values of course.
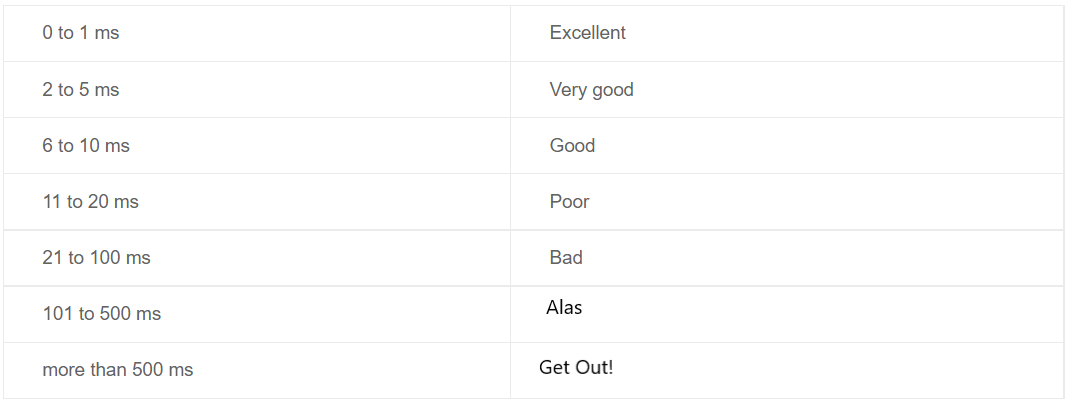

The thing to note here is actually the values you see above 101 ms. If you see between these values, it means that there is a disk-based bottleneck, no matter how good you can do at the database level.
In our example, we can easily see that the disk latency of tempdb data and log files is problematic. This data is reset when SQL Server is restarted.
In SQL Server, it is important to have the database files on different physical disks as much as possible. The script below shows the traffic on the drives where the database files are located.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
select left(mf.physical_name, 1) as drive_letter, sample_ms, sum(vfs.num_of_writes) as total_num_of_writes, sum(vfs.num_of_bytes_written) as total_num_of_bytes_written, sum(vfs.io_stall_write_ms) as total_io_stall_write_ms, sum(vfs.num_of_reads) as total_num_of_reads, sum(vfs.num_of_bytes_read) as total_num_of_bytes_read, sum(vfs.io_stall_read_ms) as total_io_stall_read_ms, sum(vfs.io_stall) as total_io_stall, sum(vfs.size_on_disk_bytes) as total_size_on_disk_bytes from sys.master_files mf join sys.dm_io_virtual_file_stats(NULL, NULL) vfs on mf.database_id=vfs.database_id and mf.file_id=vfs.file_id group by left(mf.physical_name, 1), sample_ms |
As a result of this query, if most of the traffic is flowing on certain drives, it will be beneficial to move some files there to other drives.
![]()
