

ColumnStore Index entered our lives with SQL Server 2012. Normally the index is stored in the disk as row-based, and the index is created by combining these rows. ColumnStore Index is created by combining these columns. So, Its stored as column-based. This feature was typically used for the datawarehouse in SQL Server 2012. According to Microsoft, the performance of datawarehouse queries can be increased up to 10 times and the data can be compressed up to 7 times.
First, I’ll start by mentioning the properties of the columnstore index in sql server 2012, and then I’ll continue to explain what’s new in SQL Server 2014 and 2016.
With SQL Server 2012:
We are able to create NonClustered ColumnStore index.
Since ColumnStore Index stores the data as column-based, it provides performance by reading only the columns required and reducing the amount of data read.
The columns are stored in compressed form, and in this way the amount of data read is reduced and performance is increased.
Since the data is compressed, the data transferred from the disk to the memory is less, and so memory is used in a very effective way.
When we create ColumStoreIndex, the size of the table will be significantly reduced. We will examine how small the table size will be by doing an example.
When a query is executed in a table that has a ColumStore Index, a custom query execution technology runs and reduces CPU usage.
If you want to create a ColumnStore Index on a table with a Clustered Index, all of the Clustered Index columns must be in ColumnStoreIndex. If you don’t put it in the create script, sql server will automatically add these columns to the columnstore index.
It can be used with Partition, but the partition column must be defined on the columnstore index.
Normal indexes should not exceed 900 bytes. There is no such limitation in ColumnStore index.
This index structure was not used too much in SQL Server 2012. Because a table with columnstore index could not be updated. If you need to update, you had to re-create the table. Despite this, it could be used for reporting purposes.
Let’s create a sample table with clustered index with the help of the following script and add random records.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE TABLE ColumnStoreExample (ID [int] NOT NULL, CityID [int] NOT NULL, CountryID [int] NOT NULL, CityName char(100) NOT NULL, CountryName char(100)); GO CREATE CLUSTERED INDEX CIX_ID ON ColumnStoreExample (ID); GO DECLARE @counter bigint; SET @counter=0 while(1=1) BEGIN INSERT INTO [dbo].[ColumnStoreExample ]([ID],[CityID],[CountryID],[CityName],[CountryName]) VALUES (@counter,@counter,@counter,'country','country') SET @counter=@counter+1 END |
Run the above script until the table size is 1 GB. While the query is running, you can check the progress of the table size with the help of the following script.
|
1 |
exec sp_spaceused 'ColumnStoreExample' |
In my example, I have stopped the script when the table size is approximately 470 mb (as you can see in the reserved and data columns).
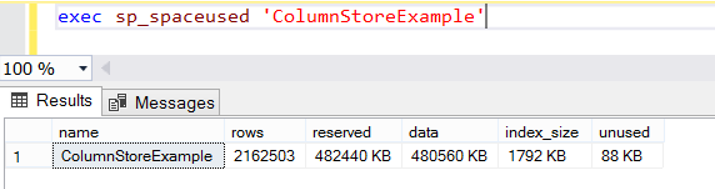

Before creating the ColumnStore Index, let’s create an index in the CityID column to look at the normal index performance.
You will see “WITH (ONLINE = ON, MAXDOP = 4)” in the index script.
I use ONLINE = ON to make this process online. Thus, the application will not lock.
I run the query in parallel with MAXDOP = 4.
You can increase the level of parallelism by writing a larger number instead of 4. I recommend that you read the following article to find the most appropriate number.
“Numa Nodes, MAX/MIN Server Memory, Lock Pages In Memory, MAXDOP”
|
1 2 3 4 5 6 7 |
CREATE NONCLUSTERED INDEX [IX_Index] ON [dbo].[ColumnStoreExample] ( [CityID] ASC ,[CountryID] ASC ,[CityName] ASC ,[CountryName] ASC )WITH (ONLINE = ON,MAXDOP=4) |
After creating the index, I’m running the following script again.
|
1 |
exec sp_spaceused 'ColumnStoreExample' |
As you can see below, index increased to 485 mb. Of course, the table size increased simultaneously.
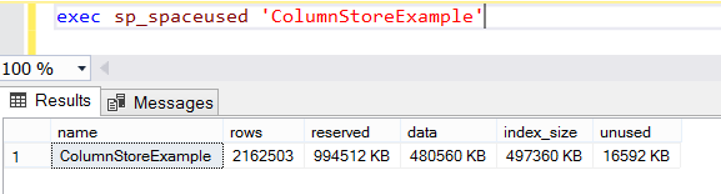

Now let’s create a nonclustered columnstore index.
|
1 2 3 4 5 6 7 8 |
CREATE NONCLUSTERED COLUMNSTORE INDEX ColumnStoreIndexExample ON ColumnStoreExample (CityID ,CountryID ,CityName ,CountryName) WITH(MAXDOP=4); GO |
After creating the non clustered columnstore index, I’m running the following script again, and I see that index size is increased by 19 mb. The size used by columnstore index decreased by 25 times according to the normal index.
|
1 |
exec sp_spaceused 'ColumnStoreExample' |
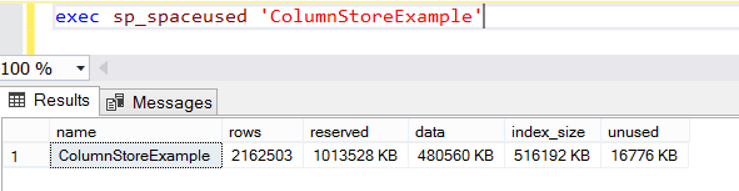

ColumnStore Index Restrictions in SQL Server 2012
- Only nonclustered columnstore index can be created. Clustered columnstore index does not exist in sql server 2012.
- There cannot be more than 1024 columns on a columnstore index.
- Cannot be created as Unique.
- Cannot be created in view or indexed view.
- Columnstore index cannot contain a sparse column.
- You can define the primary key in the table, but the columnstore index cannot be both PrimaryKey and ForeingKey at the same time.
- You cannot perform ALTER. You need to do DROP-CREATE when you want to do ALTER.
- Column cannot be added as INCLUDE. You can find the details of the include column in my article “Index Concept and Performance Effect On SQL Server“
- You cannot sort index columns as “ASC” or “DSC”. ColumnStore is sorted by index compression algorithm.
- Columnstore Index does not support index seek. Therefore, sql server does not prefer to use columnstore index if small datasets are read.
- Most importantly, if you created a nonclustered columnstore index in a table, this table cannot be updated in SQL Server 2012 🙂
Columnstore index cannot be used with the following:
- Page ve Row Compression
- Replication
- Change tracking
- Change data capture
- Filestream
What’s New for Columnstore index in SQL Server 2014
There is a new big feature: Updatable clustered columnstore index. When we create a clustered columnstore index in the table, we can not create any other index.
Delete operations are marked as deleted only and then deleted in the background, so the performance of the Delete is very fast.
The columnstore_archieve property has been announced as a compression method. We can reduce the table size even further. We can do this with the help of the following script with this compression method.
|
1 2 |
ALTER TABLE [dbo].[ColumnStoreExample] REBUILD WITH (DATA_COMPRESSION=COLUMNSTORE_ARCHIVE) |
What’s New for Columnstore index in SQL Server 2016
- We can use Snapshot Isolation and Read Committed Snapshot Isolation Levels. Read the following articles about Isolation Levels.
- The readable secondary database on the Always ON Availability Group supports the updateable columnstore index.
- A btree index can be created in a table that has a Clustered columnstore index.
- A column store index can be created in the Memory-Optimized Table.
- Nonclustered columnstore index can be “filtered”.
- A columnstore index can be created when creating a table.
- Updateable nonclustered columnstore index can be created.
In the following table I received from docs.microsoft.com, you can find features supported by the columnstore index according to the versions.
| Columnstore Index Feature | SQL Server 2012 | SQL Server 2014 | SQL Server 2016 | SQL Server 2017 | SQL Database Premium Edition | SQL Data Warehouse |
| Batch execution for multi-threaded queries | yes | yes | yes | yes | yes | yes |
| Batch execution for single-threaded queries | yes | yes | yes | yes | ||
| Archival compression opti on. | yes | yes | yes | yes | yes | |
| Snapshot isolation and read-committed snapshot isolation | yes | yes | yes | yes | ||
| Specify columnstore index when creating a table. | yes | yes | yes | yes | ||
| AlwaysOn supports columnstore indexes. | yes | yes | yes | yes | yes | yes |
| AlwaysOn readable secondary supports read-only nonclustered columnstore index | yes | yes | yes | yes | yes | yes |
| AlwaysOn readable secondary supports updateable columnstore indexes. | yes | yes | ||||
| Read-only nonclustered columnstore index on heap or btree. | yes | yes | yes* | yes* | yes* | yes* |
| Updateable nonclustered columnstore index on heap or btree | yes | yes | yes | yes | ||
| Additional btree indexes allowed on a heap or btree that has a nonclustered columnstore index. | yes | yes | yes | yes | yes | yes |
| Updateable clustered columnstore index. | yes | yes | yes | yes | yes | |
| Btree index on a clustered columnstore index. | yes | yes | yes | yes | ||
| Columnstore index on a memory-optimized table. | yes | yes | yes | yes | ||
| Nonclustered columnstore index definition supports using a filtered condition. | yes | yes | yes | yes | ||
| Compression delay option for columnstore indexes in CREATE TABLE and ALTER TABLE. | yes | yes | yes | yes | ||
| Columnstore index can have a non-persisted computed column. | yes |
*To create a read-only nonclustered columnstore index, store the index on a read-only filegroup.
![]()
