 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
This article contains information about SQL Server indexes and performance effetc of indexes.
What is Index in SQL Server?
Indexes allow us to access data faster and with less reading.
As a concrete example, if you do not have a catalog page in a book, consider how you will find what you are looking for in the book.
You need to read the entire book from start to finish. In order to find a record of a select statement in a table without a index, it is necessary to read the entire table in this way.
This process is called table scan. This is a situation we do not want to see when we look at the execution plan of the query when performing performance improvement.
For more detailed information on the Execution Plan, we recommend reading the article entitled “What is Execution Plan On SQL Server“.
Imagine that you have a catalog of contents inside the book. You can find what you want in the book by reading less and more quickly using this catalog. We can easily find the data we are looking for by using index.
Indexes work on B-tree structure.
What is B-tree Index in SQL Server?
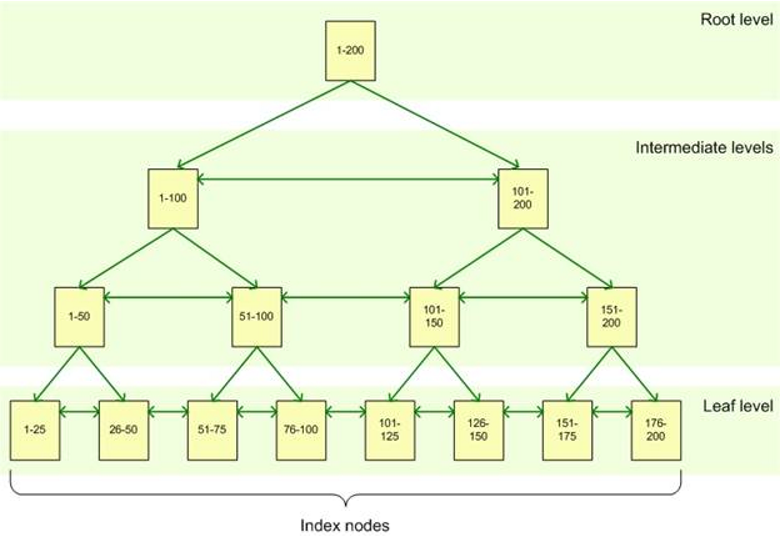
B tree structure consists of 3 layers. You can see the detail in the picture below.
Let’s examine the following picture in more detail with an example.
In our table we have values from 1 to 200. Let’s create an index on this column.
Root Level: Root Level is the top page in the Btree tree structure. When an index is searched, the search starts from Root Level and continues to find the data needed to the bottom of the tree.
As you can see in the picture, Root Level Page has values from 1 to 200 in this index. You can see which intermediate level we need to go to find the data we are looking for.
Intermediate Levels: After the Root Level Page, there are intermediate level pages. Depending on the size of the index, there are one or more intermediate levels.
In the example below you see 2 intermediate levels. For example, let’s say we are looking for a record number 123. First we go to root level. Then we go to the page in the intermediate level, which points to values between 101 and 200. Then on this page it leads us to the other intermediate level page which points to the values between 101-150.
Leaf Level: Leaf Level is the last part of the Btree structure. If we continue with our example, the search will be directed to the leaf level page 101-125 when it arrives at the intermediate level page that points to records 101-150. Depending on the type of index (Clustered or Non Clustered), the level at which the pointer is pointing to the location of the data or the data.
To examine the differences between the Clustered and Non Clustered Indexes in detail, we recommend reading the article “Difference Between Clustered Index and Non Clustered Index“.
We should be careful when creating Indexes. We need to decide whether to create an index based on transaction loads in the database and the intended use of the database.
For example, if there are many updates or inserts or deletes, we should be careful about creating indexes in this table. Because every update or insert or delete operation will be applied to the index.
Therefore, if you create an index, update, insert and delete operations will slow down.
We must warn the application developer about this. However, if there is a query with too much overhead, we can choose to create it if an index will speed up this select seriously.
If we do not have a lot of updates, inserts, and deletes, and usually application uses select, we can create indexes in order to increase the select performance.
You can index multiple columns by putting them together. Such indexes are called composite indexes.
For example, we have a query like;
1 | select a from table1 where b = 3 and c = 4 |
You can set the index to include both column b and column c.
You can create the index with more than one column, but the size of the index must not exceed 900 bytes.
If the size of the index you want to create is more than 900 bytes, you will get a warning like this.
Warning! The maximum key length is 900 bytes. The index ‘a’ has maximum length of 3402 bytes. For some combination of large values, the insert/update operation will fail.
If you want to insert an index larger than 900 bytes in size, you may get an error like this.
Msg 1946, Level 16, State 3, Line 11
Operation failed. The index entry of length 3402 bytes for the index ‘a’ exceeds the maximum length of 900 bytes.
Actually , 900 bytes is too big. I always look at the number of columns in the table before creating an index in the table.
For example, you have 20 columns in the table and you need to create an index with 3 columns and 2 included columns.
If this index will increase the performance of the application too much, you should consider to create it.
But I never create the index if it has more than 3 or 4 columns on a table which has 20 column.
What is included column in SQL Server?
Suppose we create a non-clustered index for column A in a table with a clustered index. We get a question like the following.
1 | select B from table1 where A=3 |
The query will search for the index on column A and find the clustered index key when it reaches the leaf level. Then, by going to the clustered index with this clustered index key information, you will find the data you need. This process is called key lookup.
We need to put column B in the index A as the included field, so that we can retrieve the data we need using index only, without performing Key lookup. This type of nonclustered indexes is called Covering Index.
As I told you at the beginning of the article, indexes are kept separate from the tables on the disk and insert, update and delete operations on the table are applied to the indexes. So the indexes become fragmante.
How does “index fragmentation” occur?
We created our index. And we executed update, delete and insert for a while.
Suppose we deleted a record from a page of index. Then we wanted to insert another record. If there is not enough space in this page, new record will be written in a new blank page.
In this way, the indexes will be fragmented over time and the performance of the index decreases as the fragmentation increases. If there is too much updates and deletes, you should think about using “fill factor” to prevent the indexes from becoming fragments quickly.
What is Fill factor?
When creating or rebuilding your indexes, you can specify the fill factor parameter.
For example, if you set the fill factor as 90%, SQL Server will fill 90% of Leaf Level pages and leaves 10% blank.
In this way, if you want to add a record to the leaf level page, you will find the empty space and delay fragmentation.
You can set Fill Factor according to the speed of fragmentation of your index. But remember that, your index’s leaf level size will increase , because it will add free space at the end of the pages.
We told you that we added a space at the end of the Leaf Level pages with the fill factor.
What is Pad Index?
If we set the fill factor when creating or rebuilding the index, we can use the pad_index = on option.
If Pad_index is enabled, the space at the Leaf Level pages is also set at the intermediate level. But I can not say that it is very important in terms of performance.
I generally set Fill Factor to 90% at server level.
You may want to read the article titled “sp_configure(Server-Level Configurations in SQL Server)“.
I leave Pad_Index off. Of course, in some cases you can set the fill factor specifically for some indexes to 80% or even 70%. It’s all about how often your index will be fragmented.
The fill factor option is a nice feature for us to delay the problem of frequent fragmentation of your indexes. But in the end, indexes will be fragmanted. So you should create a job to rebuild or reorganize indexes on a regular basis.
OLA HALLENGREN has prepared very nice scripts for sql server maintenance operations. I use these scripts and I recommend you to use them. I mentioned how to configure OLA HALLENGREN’s job in the article “SQL Server Maintenance“.
![]()