



In this article we will transfer the following data set from the AdventureWorks database, which is the sample database of SQL Server, to logstash with elasticsearch. If you want to move CSV or TXT File to Elasticsearch you can read the below article.
“How To Move CSV or TXT To Elasticsearch”
Source Query in AdventureWorks2014 Database
|
1 2 3 4 5 6 7 8 |
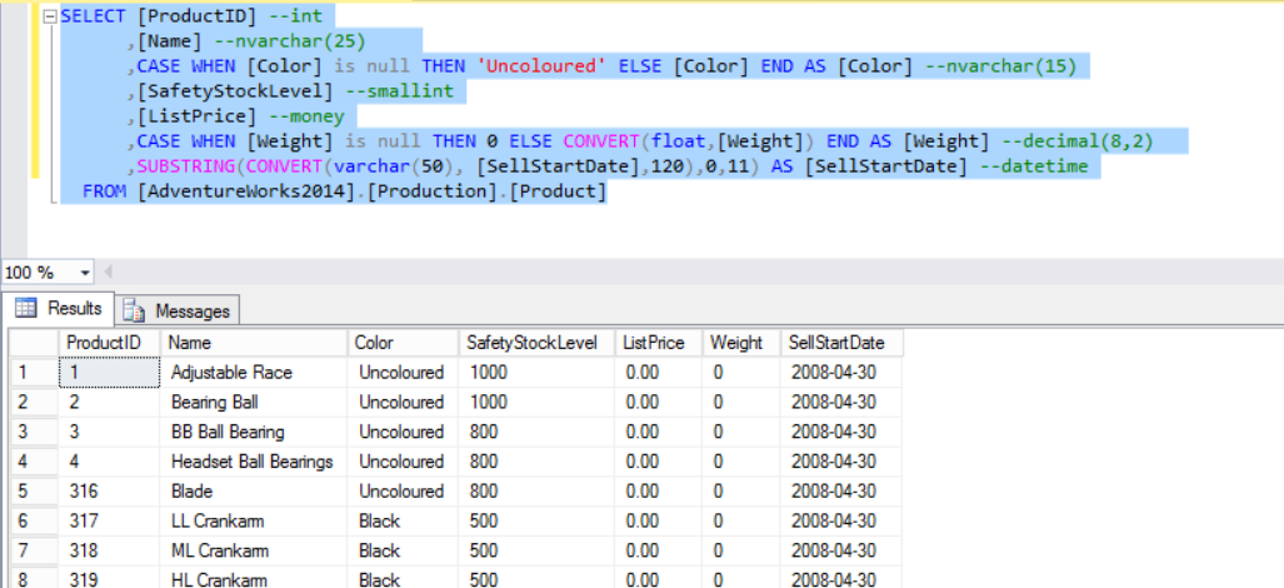
SELECT [ProductID] --int ,[Name] --nvarchar(25) ,CASE WHEN [Color] is null THEN 'Uncoloured' ELSE [Color] END AS [Color] --nvarchar(15) ,[SafetyStockLevel] --smallint ,[ListPrice] --money ,CASE WHEN [Weight] is null THEN 0 ELSE CONVERT(float,[Weight]) END AS [Weight] --decimal(8,2) to float--There will be an error if you do not convert. ,SUBSTRING(CONVERT(varchar(50), [SellStartDate],120),0,11) AS [SellStartDate] --datetime FROM [AdventureWorks2014].[Production].[Product] |

Create Elasticsearch Index With Mapping
If we transfer data from MS SQL without mapping in elasticsearch, all data is transferred as text. To transfer data with the correct data types, we need to mapping in elasticsearch.
According to the above data types, we create an index in elasticsearch as follows. You should note the replica and shard numbers. We have not specified in our example. You may want to read the following article for more information.
“How To Create an Elasticsearch Indice using Kibana”
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
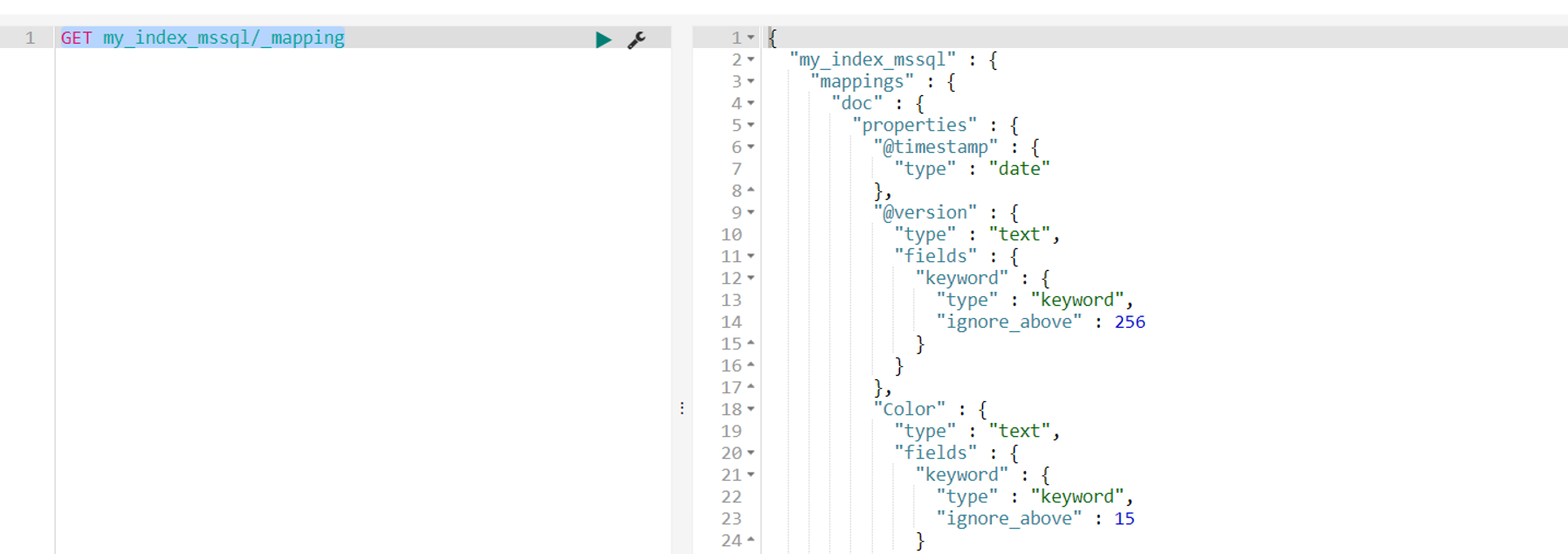
PUT my_index_mssql { "mappings": { "doc": { "properties": { "@timestamp": { "type": "date" }, "@version": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "ProductID": { "type": "integer" }, "Name": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 25 } } }, "Color": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 15 } } }, "SafetyStockLevel": { "type": "short" }, "ListPrice": { "type": "float" }, "Weight": { "type": "float" }, "SellStartDate": { "type":"date", "format":"YYYY-MM-dd" } } } } } |
We can see the mapping of the index we created with the command below.
|
1 |
GET my_index_mssql/_mapping |

In order to transfer the data from a source with logstash to Elasticsearch, we need to prepare a conf file on the server where logstash is installed.
Download SQL JDBC Driver
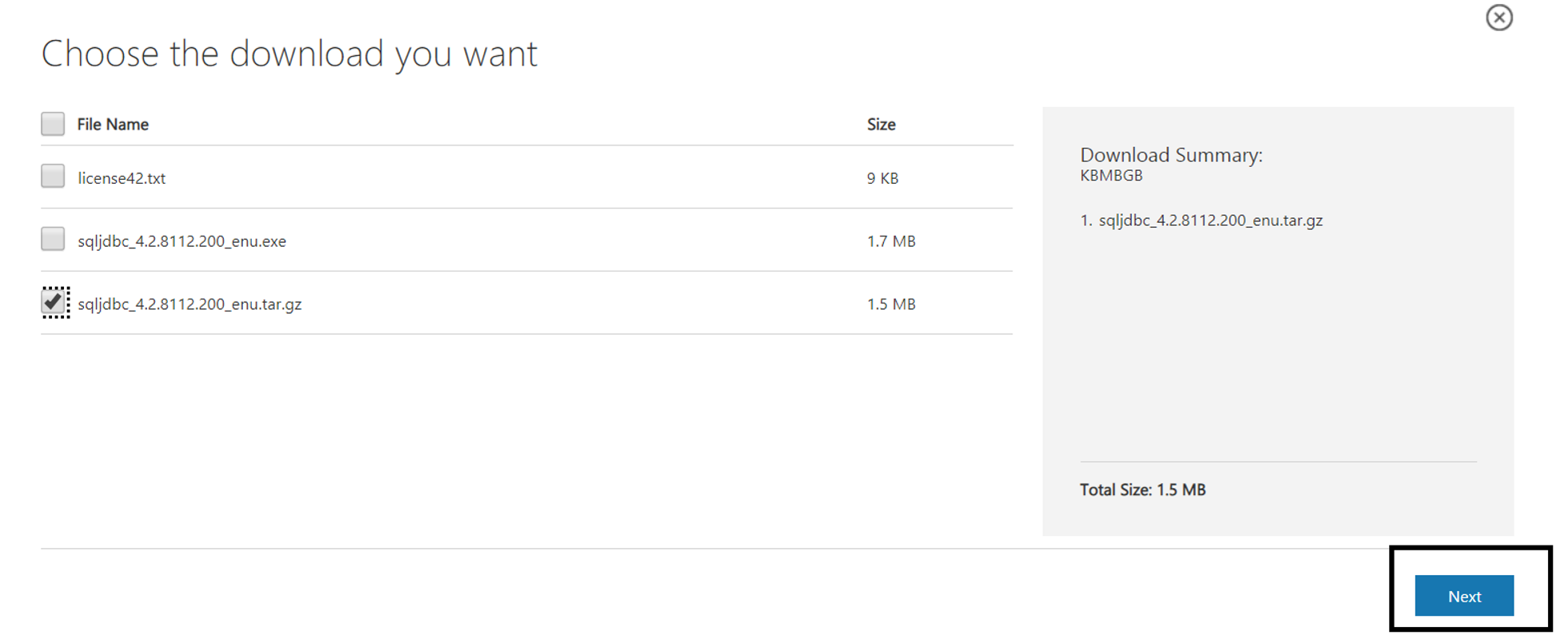
We should download SQL JDBC Driver before configuring the .conf file.
https://www.microsoft.com/en-us/download/details.aspx?id=54671

After downloading the file, we copy it to the server where logstash is installed. I copied it to /home/elasticsearch using xshell’s file transfer.


Then go to the /home/elasticsearch directory using the following command.
|
1 |
cd /home/elastic/ |
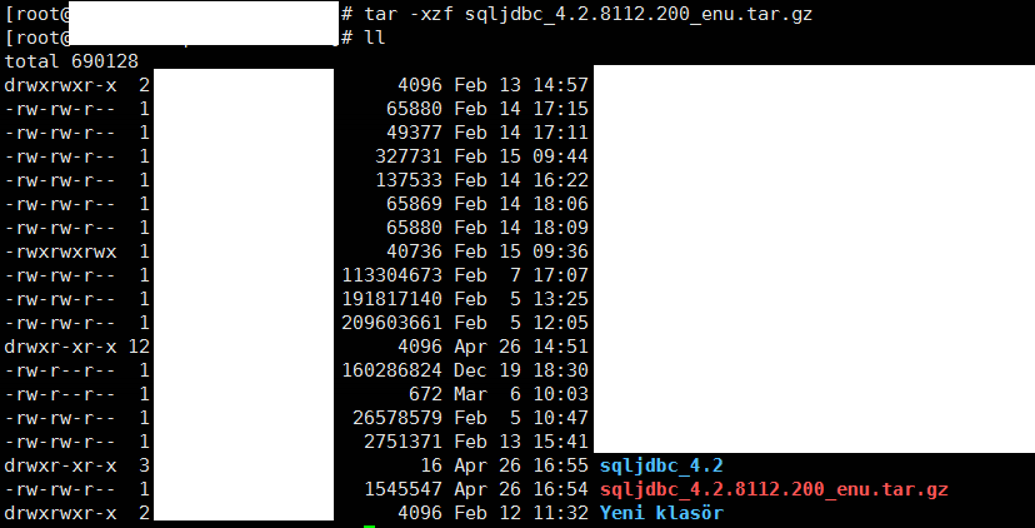
Extract the file.
|
1 |
tar -xzf sqljdbc_4.2.8112.200_enu.tar.gz |

Configure the .conf File on the Server Where Logstash is Installed
Create the conf file in the /etc/logstash/conf.d/ directory as follows, and save it as mssql_dataset.conf. This directory may change in later versions. You should find the “conf.d” directory and create the .conf file in this directory.
|
1 |
cd /etc/logstash/conf.d/ |
|
1 |
vi mssql_dataset.conf |
![]()

Explanation of mssql_dataset.conf
|
jdbc_driver_library |
Find sqljdbc42.jar in the file we extracted above and write this directory |
|
jdbc_connection_string |
write your ip, port, username that will connect to SQL Server, and user password |
|
jdbc_user |
username that will connect to SQL Server |
|
jdbc_password |
password of the user |
|
statement |
sql query |
|
hosts |
write logstash ip |
|
user => elasticsearch_authorized_user password => elasticsearch_authorized_user_password |
We can Secure Elasticsearch using Search Guard. If you installed Search Guard, write the elasticsearch user and password in here. |
|
document_id |
This column must be unique for constantly transferring changed data to elasticsearch. If you do not define this parameter, logstash can not transfer changed data. |
Content of mssql_dataset.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
input { jdbc { jdbc_driver_library => "/home/elastic/sqljdbc_4.2/enu/jre8/sqljdbc42.jar" jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver" jdbc_connection_string =>"jdbc:sqlserver://172.14.243.23:1434;user=logstashUser;password=myfunnypassword;" jdbc_user => "logstashUser" jdbc_password => "myfunnypassword" schedule => "* * * * *" --works every one minute. This works like crontab. statement => "SELECT [ProductID] --int ,[Name] --nvarchar(25) ,CASE WHEN [Color] is null THEN 'Uncoloured' ELSE [Color] END AS [Color] --nvarchar(15) ,[SafetyStockLevel] --smallint ,[ListPrice] --money ,CASE WHEN [Weight] is null THEN 0 ELSE [Weight] END AS [Weight] --decimal(8,2) ,SUBSTRING(CONVERT(varchar(50), [SellStartDate],120),0,11) AS [SellStartDate] --datetime FROM [AdventureWorks2014].[Production].[Product]" type=>"doc" #our type name is doc. Look at mapping script } } output { elasticsearch { hosts => "172.14.243.24" index => "my_index_mssql" # we write our index name in here. document_id => "%{productid}" # use lower case. user => elasticsearch_authorized_user password => elasticsearch_authorized_user_password } } |
Start Logstash and Transferring Data
Then I start the transfer with the help of the following command.
|
1 |
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/mssql_dataset.conf --path.data=/etc/logstash/ --path.settings=/etc/logstash/ |
Because we schedule logstash to run every minute, it will check the records as follows.
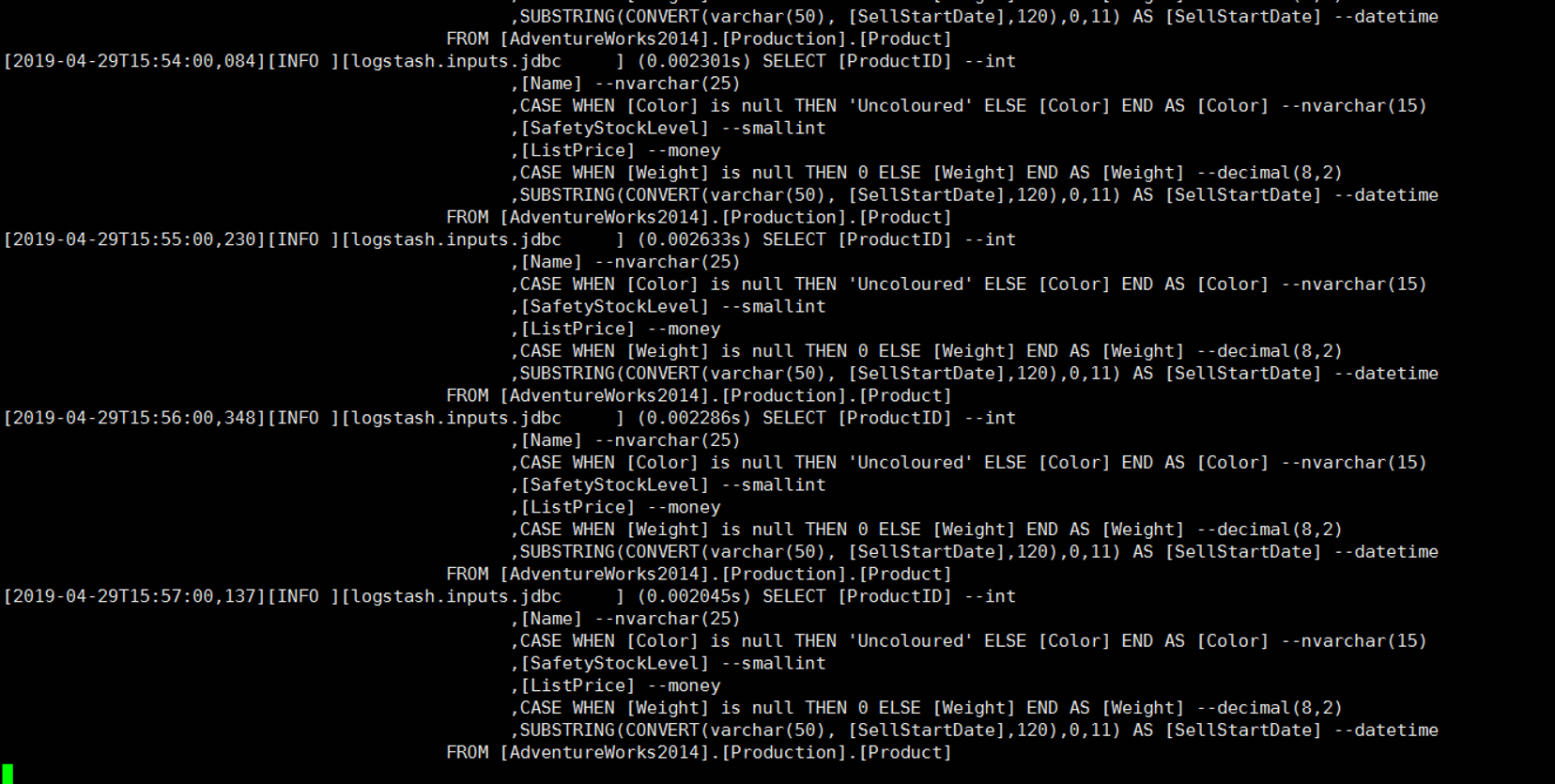

If you close the session, logstash will stop working. You can run the above script to start the logstash again. Also you can run this script with nohup or you can use screen method.
nohup:
|
1 |
nohup /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/mssql_dataset.conf --path.data=/etc/logstash/ --path.settings=/etc/logstash/ & |
When I run the above command and check the nohup.out, I saw the below error.
|
1 |
cat nohup.out |
Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the “path.data” setting.
![]()

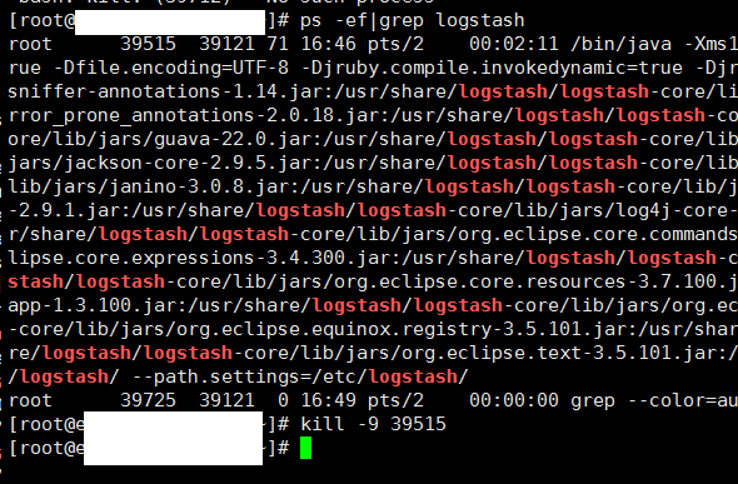
Close the all sessions and run the command with nohup or find the logstash sessions and kill.
Then you can run the command with nohup without error.
|
1 2 |
ps -ef|grep logstash kill -9 number_of_logstash_pid |

How To See Tranferred Data on Kibana
Let’s see our data through the kibana by creating an index pattern.
We are connecting to Kibana to create an index pattern and click on discover. You can install Kibana by using the following article.
“How To Install Kibana On Centos”
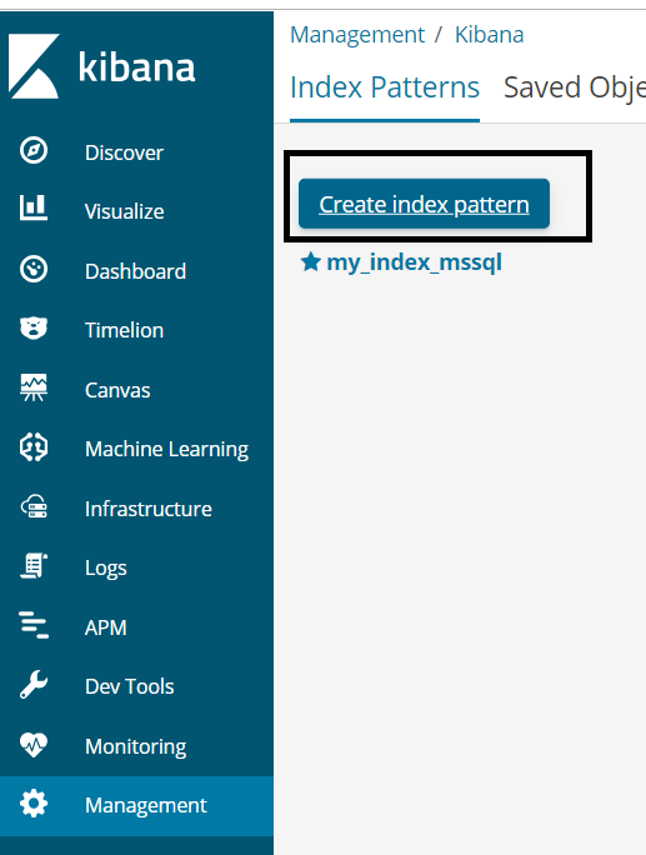
Go to the Management tab and click “Create index pattern”.

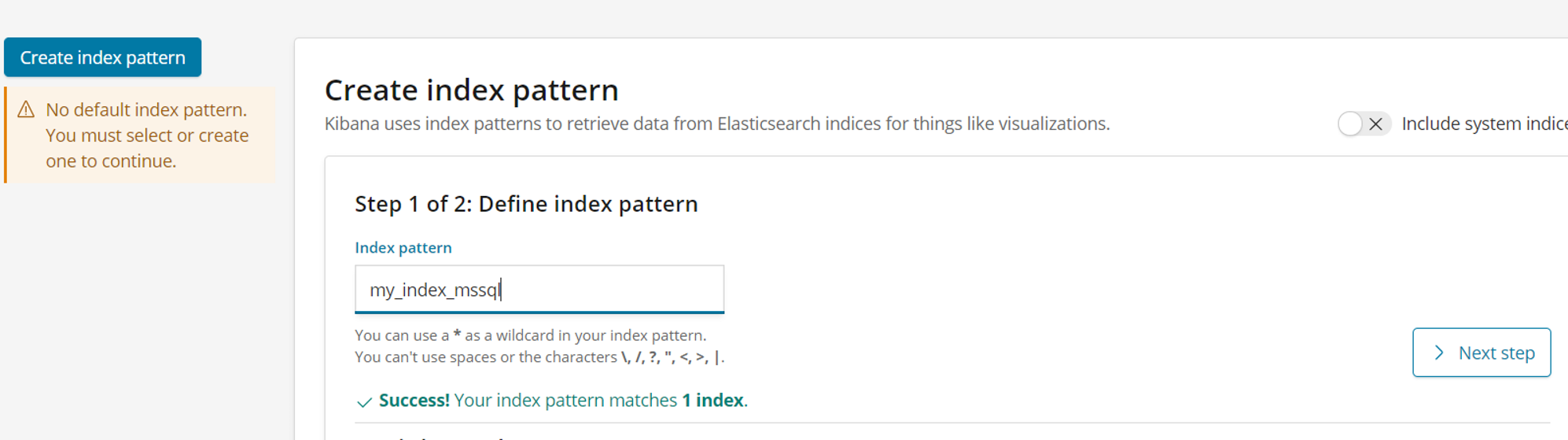
Write the name of your index and click next in the index pattern section.

On the next screen, we select a date field from the “Time filter field name” section. Data can be filtered according to the date field we selected here. Timestamp means the date on which data is transferred to elasticsearch.
Finally, we click on Create Index Pattern.
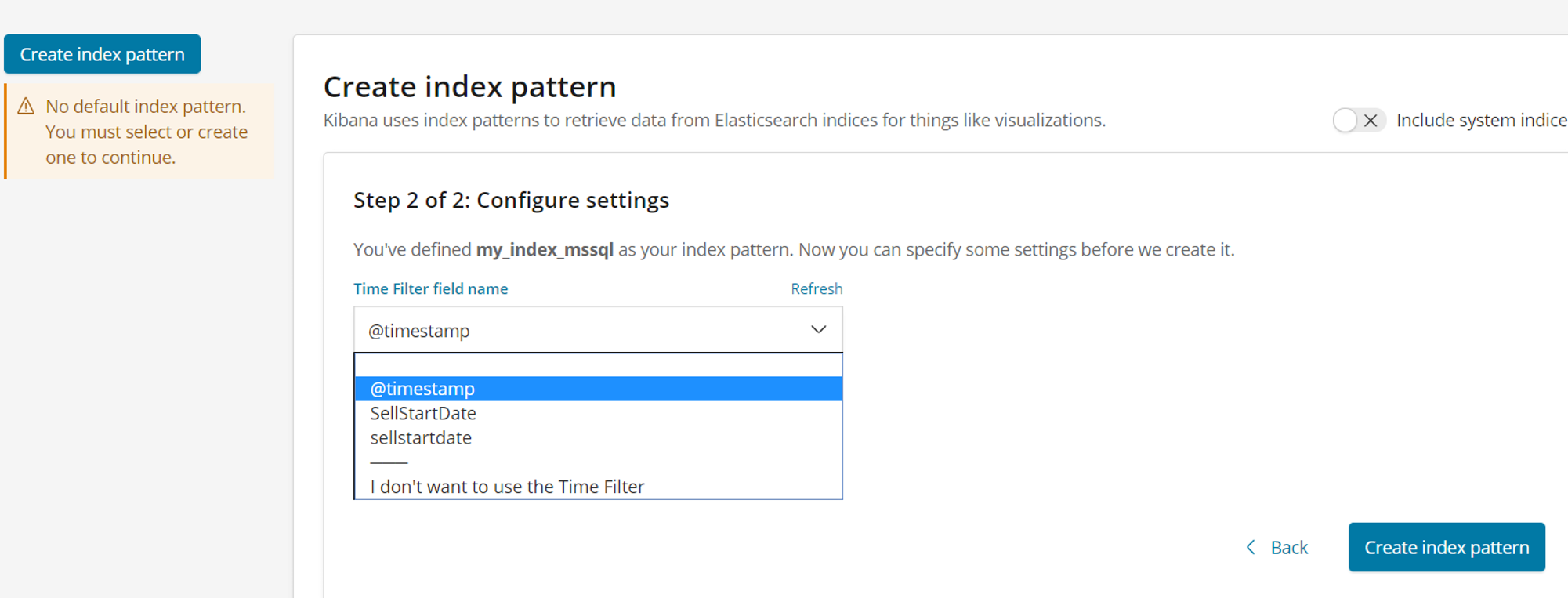

After creating the Index Pattern, we can see our data by selecting the date range as below.
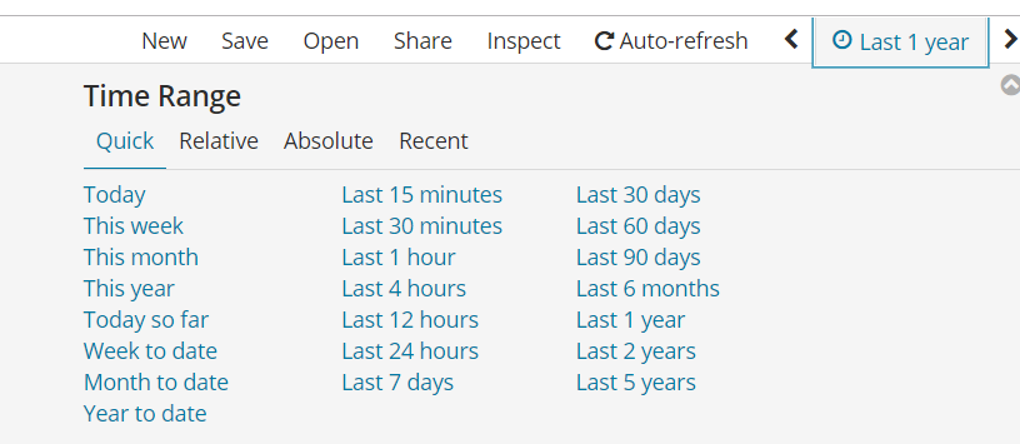

Or we can put filters as below.
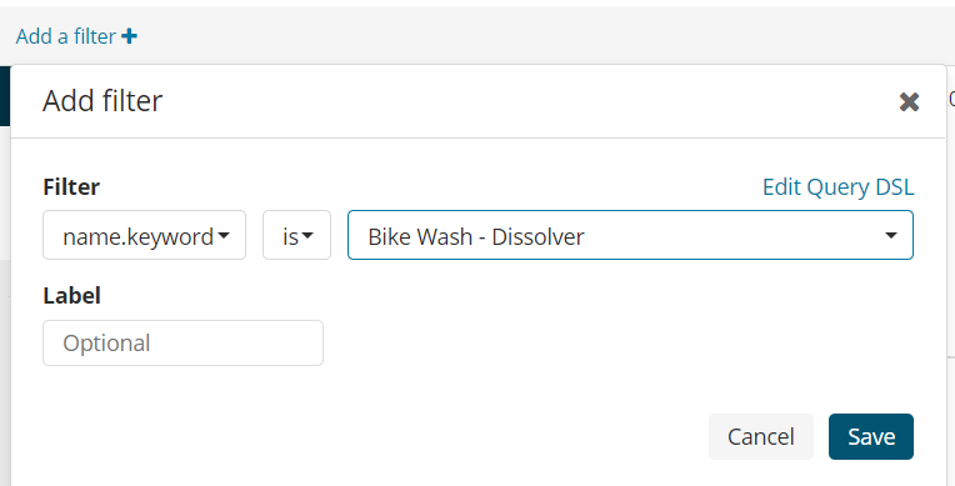

![]()
