 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
Sometimes you may need the transfer table from SQL Server to HDFS. In this article we will examine that but first you may want to know more about Sqoop.
What is Apache Sqoop?
Apache Sqoop is an open source tool developed for data transfer between RDBMS and HDFS (Hadoop Distributed File System). The name Sqoop was formed by the abbreviation of SQL-to-Hadoop words. For detailed information: Apache Sqoop
In the example, we will work on the version of SQL Server 2014. As Hadoop distribution, we will use the VM image(single node cluster) prepared by Cloudera for test, management, development, demo and learning. Download link: Cloudera QuickStart VM
After downloading the VM image, you should definitely check the hash of the file. SHA1 for VMware image: like f6bb5abdde3e2f760711939152334296dae8d586 ..
Preparation
For testing, we will transfer any dimension or fact table we select from the AdventureWorksDW2014 database (warehouse) to HDFS. For database backup: AdventureWorksDW2014
Check Java Version
First of all, we need to make sure that we access the instance. Also, “java -version” command is enough to check which java version is installed in vm. The version will be required in the next steps.
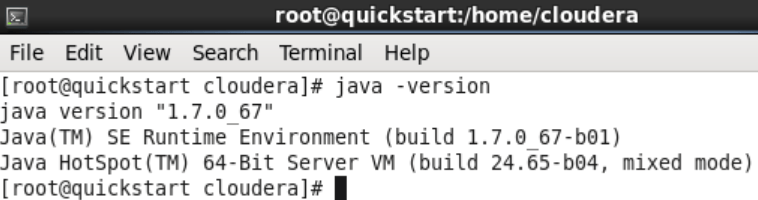
In this example, we see that the java version is 1.7. ~.
Install jdbc driver
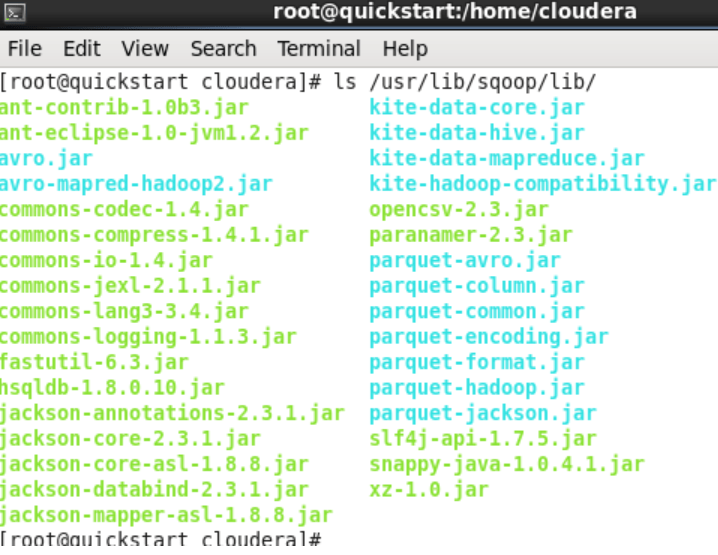
After the Java check, we have to make sure that the jdbc driver that will provide the transfer is in the sqoop library. To check this, after running “ls /usr/lib/sqoop/lib” command, we need to see the file with the .jar extension that starts with the name “sqljdbc_ ~” in the output. If it is not available, we should follow the steps below.
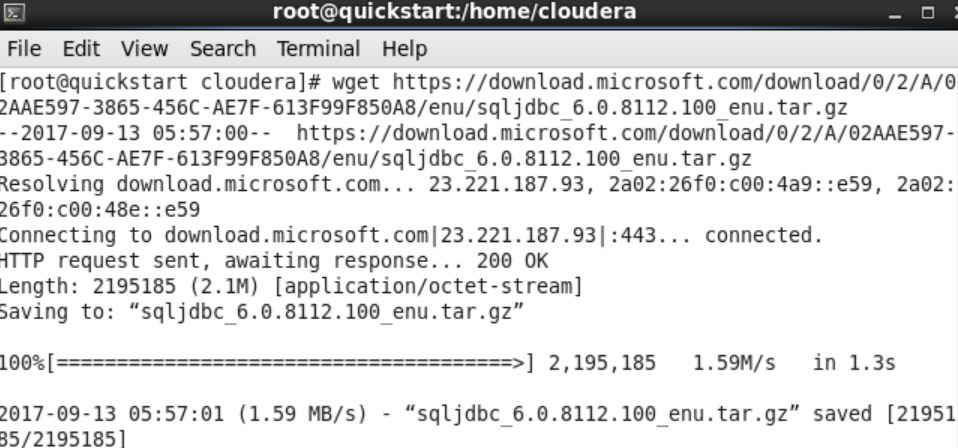
We download the jdbc driver by running the command “wget https://download.microsoft.com/download/~/enu/sqljdbc_~” on the VM on the terminal. I do not give the full link in order not to be misleading as the driver can be updated constantly. As an example, you can review the screenshot of the command I entered. Download link: Microsoft JDBC Driver 6.0 for SQL Server
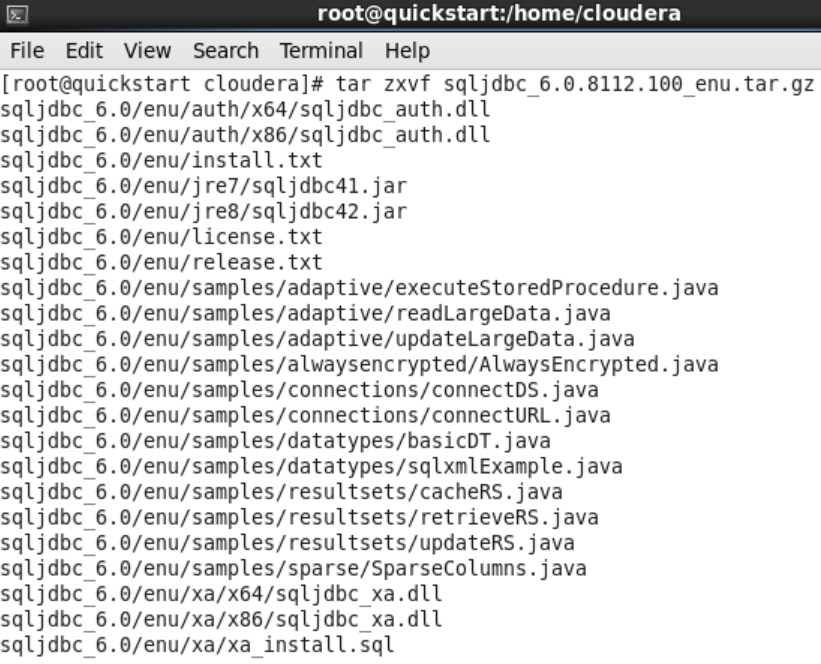
After downloading the file, we need to extract it from zip and copy it to the relevant directory. For this process, it is enough to run “tar zxvf sqljdbc~.tar.gz” command in the terminal. After extracting the zip, we need to copy the relevant jar file under the sqoop library path, depending on the java version we learned above. For this, we run the command “sudo cp -p sqljdbc_6.0/enu/jre7/sqljdbc41.jar /usr/lib/sqoop/lib/“.
Transfer Table from SQL Server to HDFS
After completing the processes above, we can transfer the data. In order to perform data transfer, we configure and run the following commands according to the environment we have. For example, “sqlserver://dev-mssql\sql2014” refers to the server name where the SQL Server instance is installed, and the SQL2014 instance name. IP address can be used instead of server name.
1 | sqoop import –connect ‘jdbc:sqlserver://dev-mssql\sql2014;database=AdventureWorksDW2014’ –username ‘hadoop’ -P –table DimReseller |
sqoop import: The command to transfer the table or view in RDBMS to HDFS.
–Connect: Parameter used to access RDBMS like SQL Server, MySQL, Oracle
–Jdbc: sqlserver: Driver to be used to provide access to RDBMS
–Username: ‘hadoop’: login name to access RDBMS
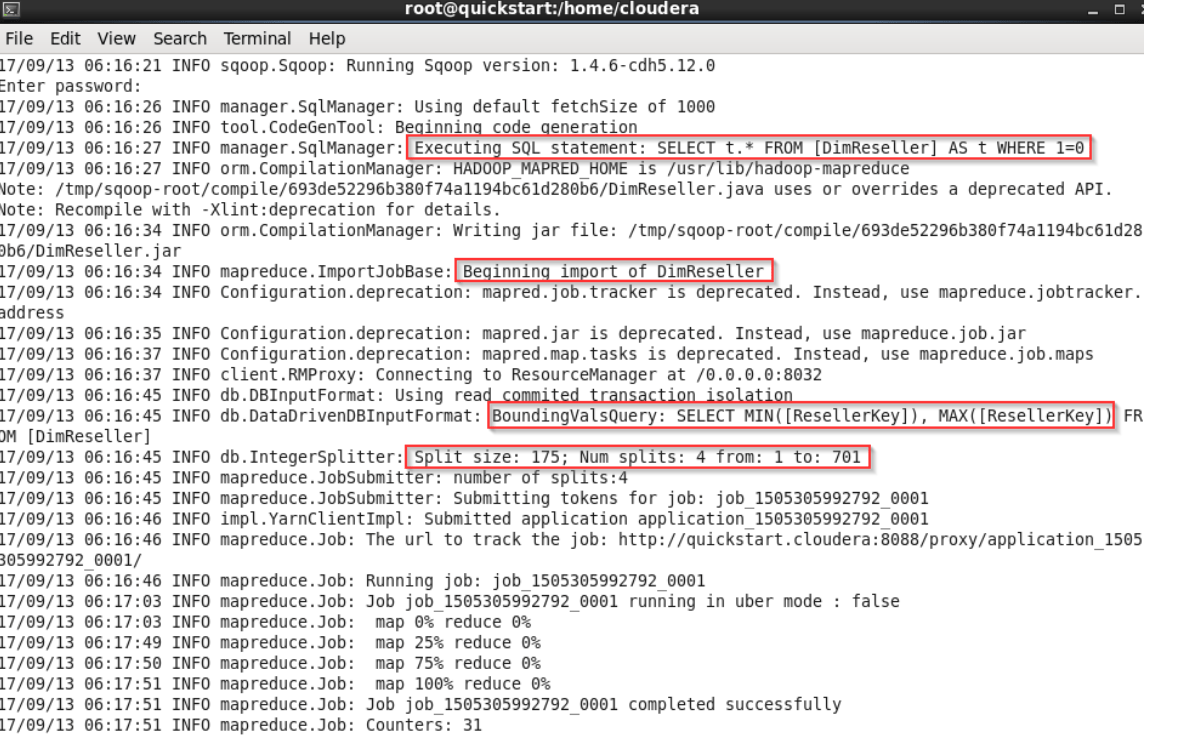
After running the command, if there is a primary key in the table, sqoop will find the MIN and MAX values for us according to the primary key and determine the amount of data to be transferred at once according to the total number of rows. In this example, the “Split size:175” and “mapreduce.JobSubmitter: number of splits:4” sections expresses this.
The last message shows the total number of records transferred. The screenshot below shows that 701 records have been transferred.
The above “number of splits: 4” value shows that 701 records will be divided into 4 parts and transferred in blocks. This will be 175×4:~701.

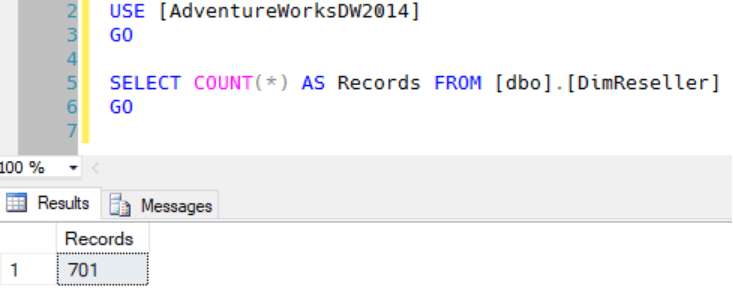
Let’s also check the number of DimReseller records in AdventureWorksDW2014.
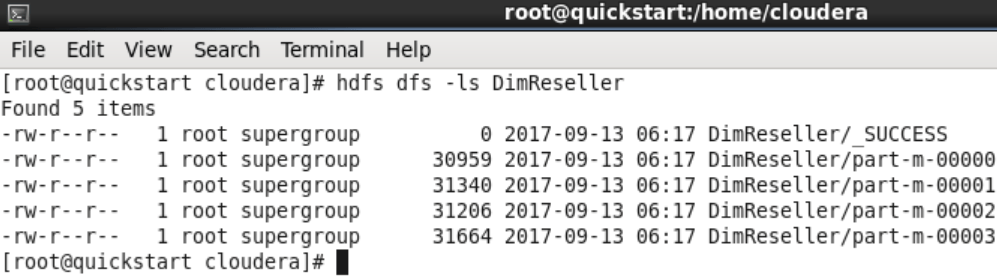
After checking the number of records, you can run the command “hdfs dfs -ls ./DimReseller”, or access the HDFS explorer from the Cloudera QuickStart interface, to check that the table is included as a file in HDFS.
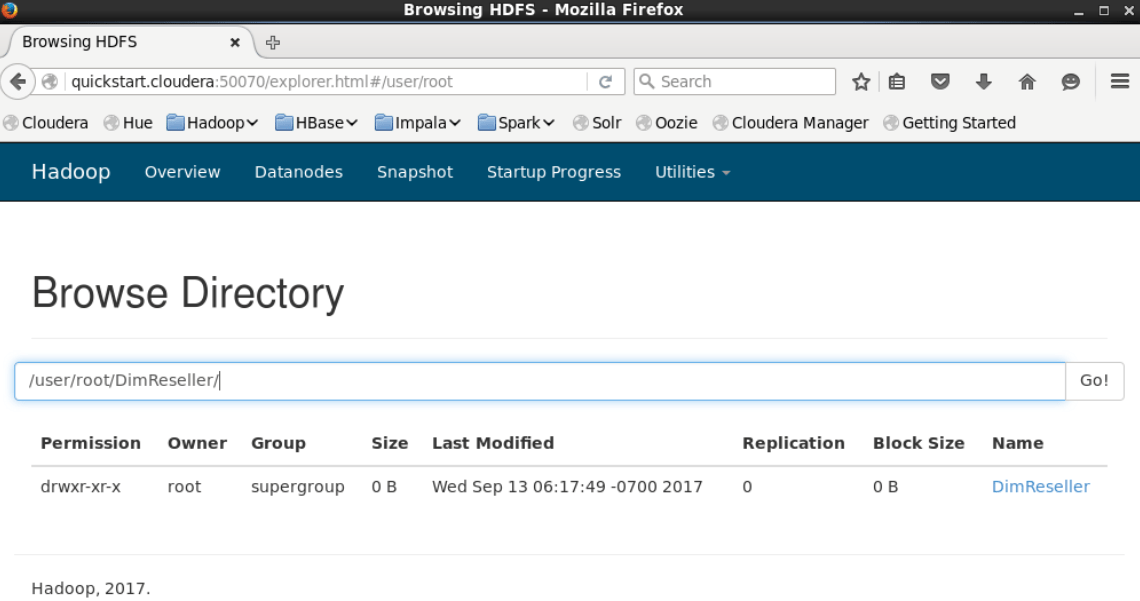
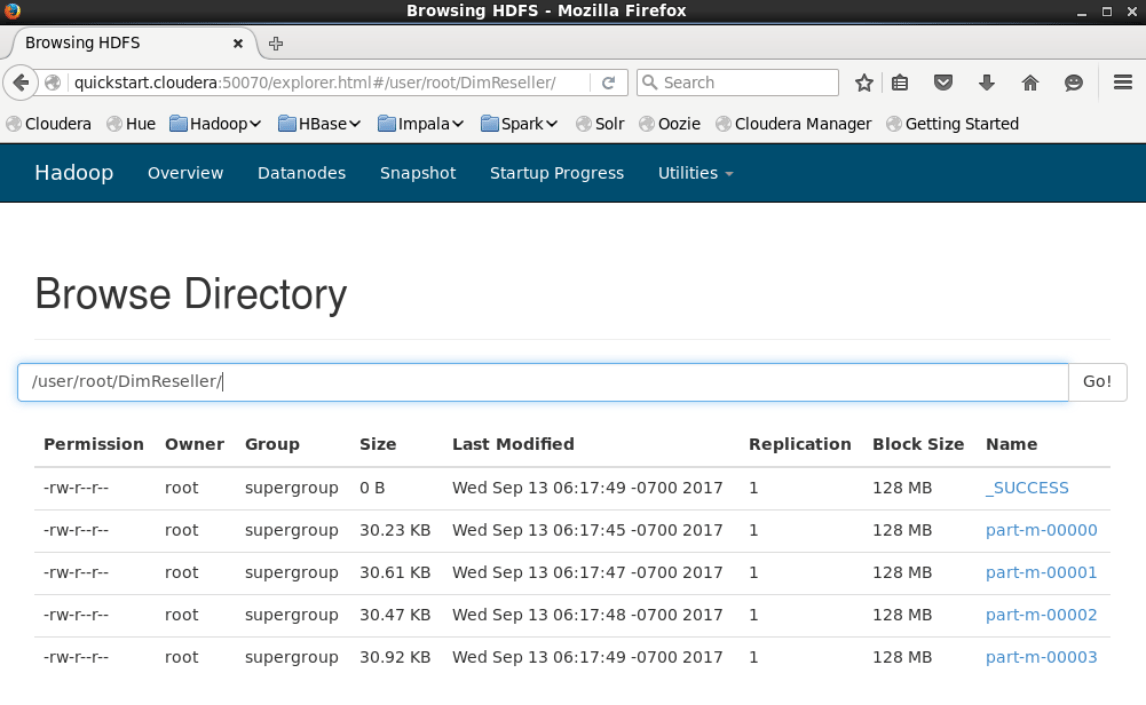
We are running the command “hdfs dfs -cat DimReseller/part-m-00000|head” in order to check the content of any part, and to list TOP 10 records, in the dimreseller which is in parts.
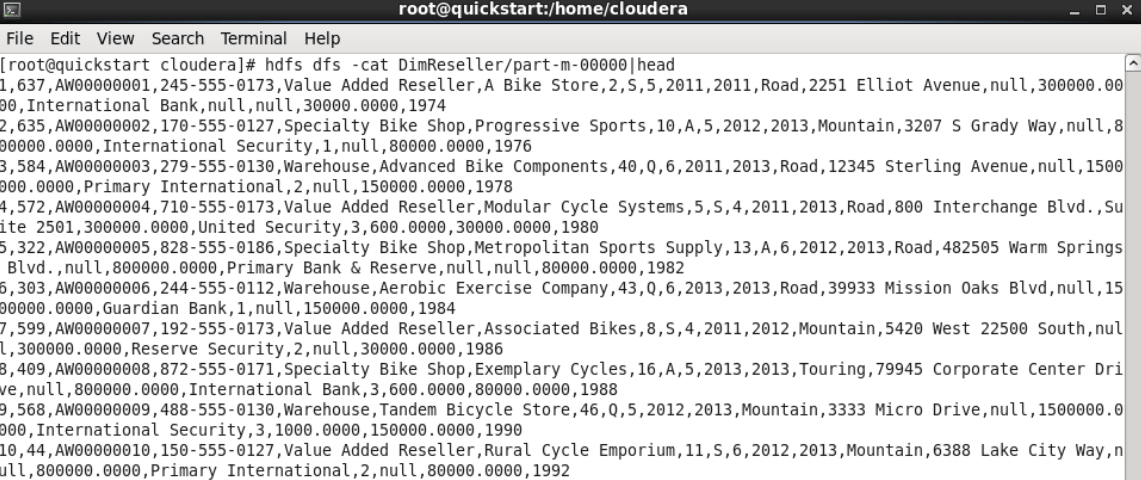
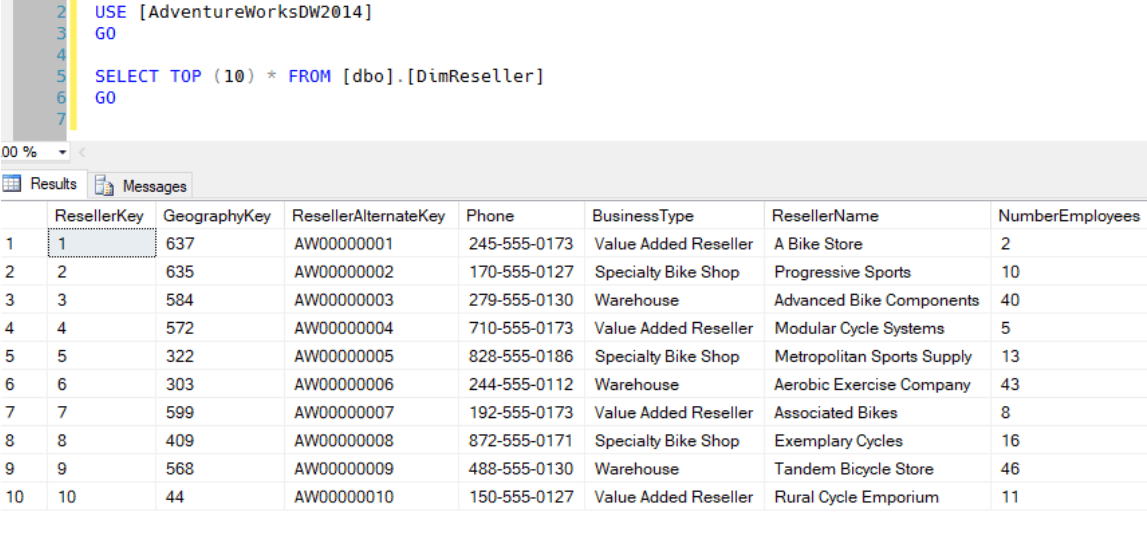
As can be seen in the screenshots, the table has been successfully transferred. After this stage, DimReseller is ready for data preparation processes for querying or batch processing.
![]()