 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
In today’s article, we will discuss the B-tree index, which is a balanced tree data structure used to store indexed values in a sorted order.
It is one of the most used index types in database systems.
It is one of the default index types in Oracle, MSSQL and PostgreSQL.
Different index types can be selected with the USING command in the CREATE index command in PostgreSQL.
If the USING command is not specified, it will use the B-tree index architecture.
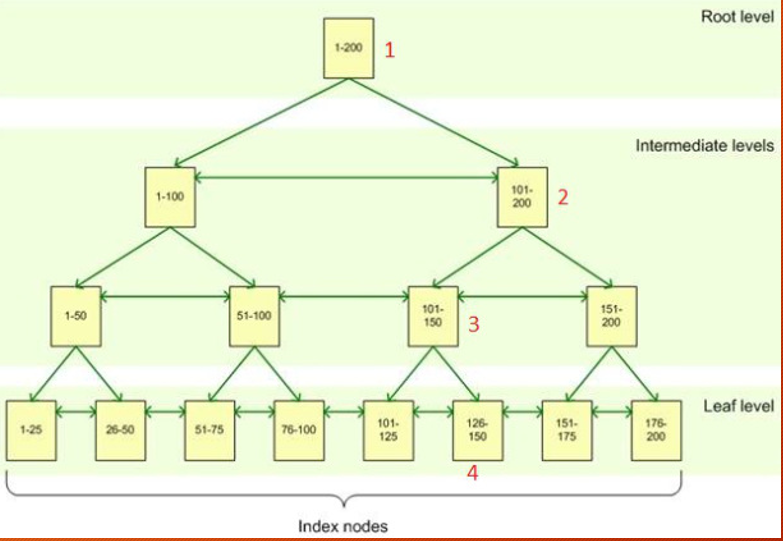
B-Tree indexes are kept in pieces as seen in the picture above.
When you want to access data in B-tree indexes, you first look at the page at the root level and if the desired data is at this root level, you go to the relevant intermediate level of this root level and from there you go to the relevant leaf level and find the data in the shortest way.
When you want to access the record numbered “22” from the B-tree structure above, you first go to the page at the Root level between “1-200”.
From here, the data is quickly returned to the user by going to the intermediate level page between “1-100” in the levels intermediate and then going to the intermediate level between “1-50” and the next one, going to the data set between “1-25” and taking the record number 24. .

You can think of a table without index as above.
It will go to all points and try to search for the records there one by one, and therefore the return of our query will be long and costly.
Non-indexed tables not only lengthen the query result, but also increase the CPU and disk usage rate and bottleneck the machine on which the database runs in terms of CPU and disk.
B-tree indexes process equality and range queries on data that can be sorted in a certain order.
In particular, the PostgreSQL query planner will prefer to use the B-tree index when a comparison is made using one of the following operators.
<
<=
=
>=
>
BETWEEN
IN
IS NULL
NOT NULL
column LIKE ‘faruk%’
column |\’faruk%’
SQL statements like above also use the B-Tree index structure.
General Usage is as follows.
1 | CREATE INDEX İndex_adi ON Tablo_Adi USING btree (Column_İsmi ); |
Example usage is as follows.
1 | CREATE INDEX ad ON "Müsteriler"("Adi_Soyadi" ) |
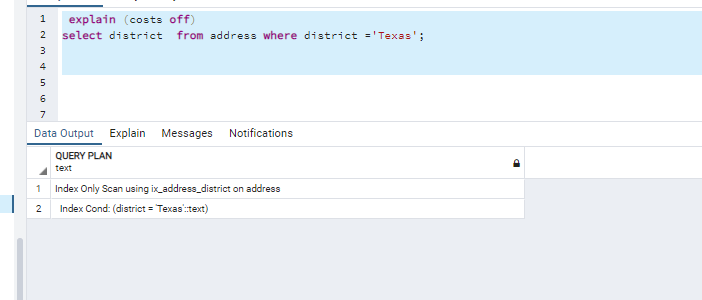
We want to fetch data containing the word “Texas” in the district column in our Address table.
When we make a normal query, we see that it performs seq scan as follows.

Since there is a district column in the where condition in our plpgsql query, we create an index for the district column as follows.
1 | create index IX_address_district on address (district) |
After the index is created, we see that it performs Index Only Scan as follows.
When defining the index, definitions can be made in the form of asc, desc, nulls, null first and null last.
Asc: Ascending is defined to create the index according to the order.
Desc: Descending is defined to create the index according to the order.
NULL FIRST: It is used to place null records in the first rows in the index.
NULL LAST: It is used to place null records in the last rows of the index.
Different operator classes can be defined when defining the index.
If you are using varchar data type, you can create varchar_pattern_ops.
Unless dealing with complex data, varchar will be sufficient.
In order to use operator classes, the collate of the database must be set to C.
If you want to see all operator classes, you can use the plgpsql command below.
1 2 3 4 5 6 | SELECT am.amname AS index_method, opc.opcname AS opclass_name FROM pg_am am, pg_opclass opc WHERE opc.opcmethod = am.oid and am.amname='btree' ORDER BY index_method, opclass_name; |
![]()