 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
In this article, we will first talk about how to configure the file group structure when the database is first created or comes from another place.
Then I’ll tell you how to transfer your tables to another file group.
Let’s talk about why you might need to create a table in another filegroup.
The database may come from another place, created on a single mdf file, and may have increased IO wait because it is too large.
In this case, you can create a new filegroup, create data files according to the data size and the number of disks in the file group you created, and spread your table to the new filegroup so that your table is evenly distributed.
You can do this by partitioning your existing disk system in the backend. But this provide frontend I/O too. Thus its necessary sometimes.
You can plan this with your friends in the system group.
There may be another drawbacks that all of the large tables remain on a single file.
For example, suppose we have 3 big tables in a database with 10 TB size.
Assume that table A is 3 TB, table B is 2 TB, table C is 1 TB.
If all these tables are in the same file group, the backup operation may be a problem.
But if each table is on a different file group, you can overcome this problem by taking a file group backup.
Also, it is not recommended that the entire database be on the mdf file since the system objects are on the mdf file.
In a large database that has just grown up on the mdf file, you can not get a response even if you fetch a fragmented index query if your indexes are not in a separate file group.
In this case, the tables on the mdf file should be distributed to the new file groups.
In the first design phase it is more advantageous to create a new file group instead of PRIMARY file group and select this file group as default if it is known that the database will grow (I follow this method in databases that will grow up over than 500 GB).
You can specify the number of file groups and the number of files according to the size of the database and the tables to be created.
For better performance of your indexes, it is useful to create them on a separate file group.
You can specify the number of files in the filegroup that you will create for the indexes according to the size of the indexes.
One reason for moving your tables to a new filegroup is that the files in the existing filegroup are unevenly distributed over the files.
If you start with a single file at the beginning and the new files are added as the data size increases, the tables will be unevenly distributed.
The Clustered Index Rebuild process will never completely resolve this problem.
Because in the clustered index rebuild process, the sql server engine first looks at how many files the table is spread over.
It then look at the size of these files and the amount of empty space they contain.
And each time it writes more data into the file it will have more free space in the file.
In this way, after each rebuild, the empty file will be more full and the full file will be empty.
So it would be a better way to create a new file group and move the table here.
I will talk about three method of moving the table to a new file group.
First Method:
Let’s look at how to move a table that is not very large in size and has no lob data to a new file group.
We can do this in the following way.
1 2 3 4 | CREATE UNIQUE CLUSTERED INDEX PK_XXX on dbo.Table_XXX (Column_XXX) with (DROP_EXISTING=ON) on [NEW FILEGROUP] GO |
Note: If there is a possibility of lob data in this table in the future, you should follow the second method.
Otherwise the lob data will be placed under the old file group, not in the new filegroup where you move the table.
Because when we do this with this method, the Text/Image File Group in the desing of the table will remain Primary.
Second Method:
If your table size is large and you have lob data in it and your disk is sufficient for logging, you can do this by creating a table on the new file group with the following method.
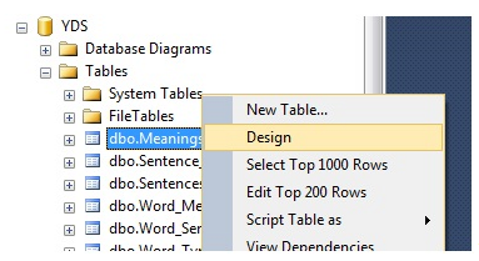
Right click on the table and choose design.
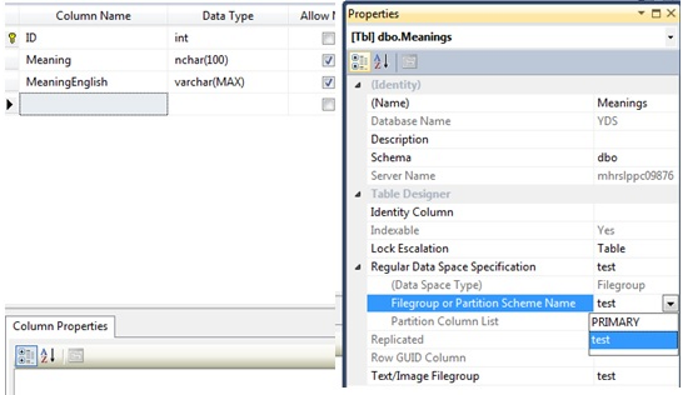
In the table design view, click on any column to open the Regular Data Space Specification tab and select the new file group from Filegroup or Partition Scheme Name. We then do the same on the Text/Image Filegroup.
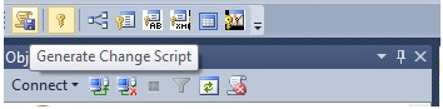
We click on any column again and click on Generate Change Script.
Note: In order to use the Generate Chance Script option, you must go to Tools-> Options-> Designers via SQL Server Management Studio and un-check the Prevent Saving Changes that require table re-creation checkbox.
After copying our script as above, we click No to close the screen and run our script as a new query.
As you can see, we can perform this operation by re-creating the table because the table has LOB data.
If we did not have LOB DATA in our table, we would be able to perform the table move using the first method.
Third Method:
In the Second Method, as you can see, the same table is recreated as Tmp_XXX and the entire table is transferred to this Tmp_XXX table with one insert.
In this case, if the table is too large, then you will also need a disk for the log file.
Even if the Recovery Mode is simple, the log will continue to grow because it is the one insert operation.
In this case, we can change the recovery mode to simple and follow the steps below.
In the second method, if we repeat the operations and generate the script with generate change script, we start a transaction before the statement that starts with “CREATE TABLE dbo.Tmp_”.
Before this transaction is closed, the “CREATE TABLE dbo.Tmp_” operation, the insert operation, and some object creation operations are performed.
You need to terminate this transaction with COMMIT before the CREATE TABLE dbo.Tmp_ statement to ensure that the entire insert operation is not in a transaction.
Of course, in this case, you must find the location where the transaction is committed in the first case of the query and remove the COMMIT statement from there.
Then you have to delete the insert operation, which is done as follows in normal query.
1 2 3 | IF EXISTS(SELECT * FROM dbo.XXX) EXEC('INSERT INTO dbo.Tmp_XXX (Tabloda bulunan kolonlar) SELECT column_1,column_2,column_n FROM dbo.XXX WITH (HOLDLOCK TABLOCKX)') |
We fill this query as follows.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | CREATE TABLE #movedrows --We make the type of the RowID the same as the primary key type of the table. DECLARE @RowCount int SET @RowCount = 10000 --According to the structure of your table, you need to increase or decrease the number. --For example, if your table is 1 TB and your row count is 100000, you can set this value to a value less than 10000. --According to the value you give here, the processing time will decrease or increase. --You will have to decide by looking at the size of your table and the number of rows in order to determine the optimal time. --Of course, you must do this in the test environment first. WHILE @RowCount > 0 BEGIN SET IDENTITY_INSERT dbo.Tmp_XXX ON INSERT INTO dbo.Tmp_XXX (column_1,column_2,column_n) OUTPUT inserted.Primary Key INTO #movedrows --You should write the name of your primary key column in the place where the Primary Key is written. --The Primary Key column of the inserted rows is being transferred to the #movedrows table. SELECT TOP 10000 column_1,column_2,column_n FROM dbo.XXX WHERE NOT EXISTS (SELECT 1 FROM #movedrows WHERE RowID = Primary Key) --You should write the name of your primary key column in the place where the Primary Key is written. --Reading 10000 rows that are not in the #movedrows table. SET @RowCount = @@ROWCOUNT SET IDENTITY_INSERT dbo.Tmp_XXX OFF END DROP TABLE #movedrows |
![]()