 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
Introduction : –
pg_rewind is a tool for synchronizing a PostgreSQL cluster with another copy of the same cluster, after the clusters’ timelines have diverged. A typical scenario is to bring an old master server back online after failover as a standby that follows the new master.
The result is equivalent to replacing the target data directory with the source one. Only changed blocks from relation files are copied; all other files are copied in full, including configuration files. The advantage of pg_rewind over taking a new base backup, or tools like rsync, is that pg_rewind does not require reading through unchanged blocks in the cluster. This makes it a lot faster when the database is large and only a small fraction of blocks differ between the clusters.
How it works :-
The basic idea is to copy all file system-level changes from the source cluster to the target cluster
- Scan the WAL log of the target cluster, starting from the last checkpoint before the point where the source cluster’s timeline history forked off from the target cluster. For each WAL record, record each data block that was touched. This yields a list of all the data blocks that were changed in the target cluster, after the source cluster forked off.
- Copy all those changed blocks from the source cluster to the target cluster, either using direct file system access (–source-pgdata) or SQL (–source-server).
- Copy all other files such as pg_clog and configuration files from the source cluster to the target cluster (everything except the relation files).
- Apply the WAL from the source cluster, starting from the checkpoint created at failover. (Strictly speaking, pg_rewind doesn’t apply the WAL, it just creates a backup label file that makes PostgreSQL start by replaying all WAL from that checkpoint forward.)
Configure Replication : –

I have already configured replication between two server [9.6 PostgreSQL community version] .
Here i have my replication setup .
Situation of fail-over :-
- DBA error
- Fail-over management tool error
- Fail-over script get wrong input which cause standby promotion .
- While doing fail-over test .
When this kind of situation occurs and we want to re-attach to connect old master as new slave in less time [Bypassing pg_basebackup/rsync] ,pg_rewind is a good solution to build new standby which start following new master .
Use case of pg_rewind :-
- Performe fail-over
- Lode some data on both server [insert some rows/create any object]
- perform pg_rewind so that old master [New standby] start following new master [old replica] .
- Check that both server are in sync and checking which was made on old master after fail-over this should get roll-backed .
Step 1 :- Promote standby server
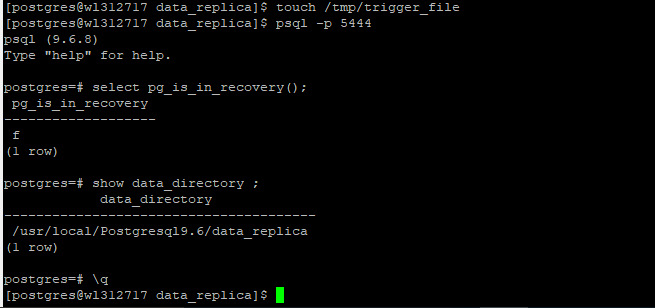
Step 2 : –Lode some data in New Master

Lode some data in Old master
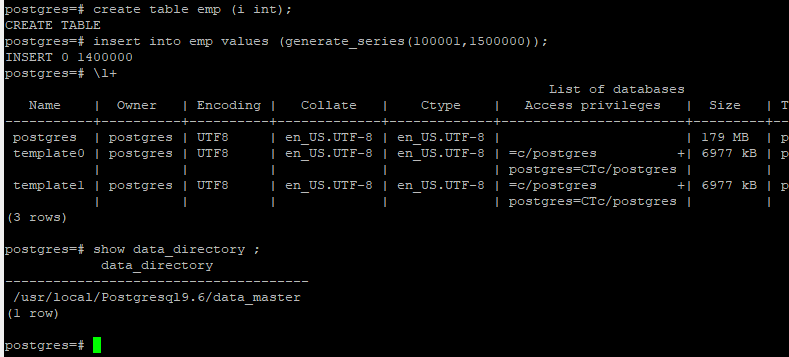
Now both server are totally out of sync ,Try to bring them in sync and old master server will start following to new master as a standby .
Step 3 : –Perform pg_rewind to start old master sync with new master .
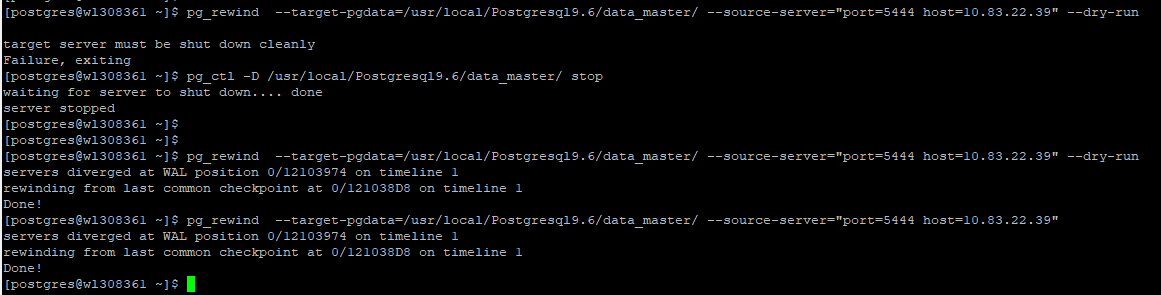
1 | pg_rewind --target-pgdata=/usr/local/Postgresql9.6/data_master/ --source-server="port=5444 host=Replica_server_ip" |
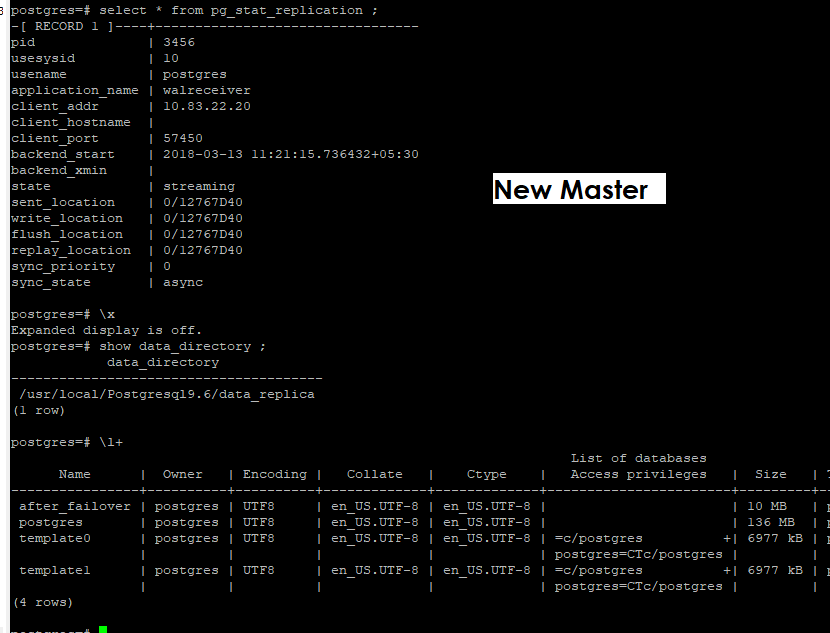
Step 4: –
Note : – Before starting new standby ,Make changes in recovery.conf to change IP address and create replication slot on master server .
Changes get roll-backed from old master which is not required and blocks which are updated those get replayed on new slave

![]()