 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
In today’s article, we will look for an answer to the question of What Is Oracle Big Data?
What is Big Data? – As a concept
“It is the concept of making large amounts of data collected over time usable and meaningful in an economical and scalable manner and where relational database techniques are not sufficient”.
The importance and value of data is increasing day by day. The reason for the increase in the importance and value of data is the increase in the amount and variety of data.
When we look at it, the roots of the Big Data concept go back to 2004. In other words, it is a concept that the world’s biggest technology giants have invested and used since 2004.
Big Data is a concept and includes open source software. The core of these software includes a series of software groups that we call Hadoop. We can list some of these software as follows;
Hadoop Core
HDFS (Hadoop Distributed File System)
Hive (Data Warehouse)
HBase
ZooKeeper
Oozie
Mahout
Sqoop
Cloudera Manager
The concept of Big Data is not limited to the above software components. The concept of Big Data is actually limited as far as you can imagine. I call this “Big Data = Imagination” and I will try to explain why “Imagination” in the rest of my article.
Big Data Concept and 4 V
Let’s talk about how we can leave the non-relational environment for a while and combine the 4 V and non-relational environment with the relational environment (RDBMS), which we know and are used to using, so that the Big Data concept can be clearly remembered.
Volume:
Perhaps the most important reason for the formation of the Big Data concept is that the volume of data we have is increasing logarithmically every day. As the volume of data increases so much, naturally the IT costs of companies increase.
It is necessary to cut down on rising IT costs and adjust the environment in which all this data is stored and managed.
Velocity:
Consider that in addition to the data whose volume is increasing, this data flows into the system very quickly and has to be met. It would be tedious and costly to load such data quickly into the relational database.
Therefore, the fact that the data flows very quickly to the system, apart from its volume, is another V that explains the concept and use of Big Data.
Variety:
Social media, sensor data, CRM files, documents, images, videos, etc. Imagine all the data, sources, and data types you can think of.
It is not possible and costly to store all of them in a relational database, even on a file system that we know.
If the diversity of data has increased and we want to process, analyze and store all this data, the concept of Big Data is the perfect fit.
Value:
When the other 3 Vs come together, another V is formed. This is value. High volumes, various and very fast flowing data entering the system must also have a value. Otherwise, cost incurred becomes value obtained.
In order for this not to happen, we need to make sense of the data we have, add value and perform analysis. Thus, the fourth V of the Big Data concept becomes value.
Oracle has developed an Engineered System for storing, storing, analyzing, adding value and reporting data and data types covering the 4 Vs I mentioned above. We named it “Oracle Big Data Appliance”.
Before moving on to Big Data Appliance, let’s talk about Hadoop and cluster structure and current approaches.
Hadoop Cluster and Traditional Architecture
As you know, Oracle develops engineering systems, which we call Engineered Systems, apart from traditional architecture.
These systems are pioneered by the Oracle Exadata Database Machine.
The aim is to present software and hardware together and to eliminate some of the problems in traditional architecture that we know and are now unfortunately used to.
For example, if there is a problem in cases where you cannot get support from a single manufacturer; The hardware team assigns the problem to the software, the software to the network team, and the network team to the hardware again.
So from manufacturer A of the hardware, manufacturer B of the software, C of the cluster, D of the network components etc. When regular problems occur, it can be difficult to get solutions and support.
Oracle Big Data Appliance
Oracle Big Data Appliance is a complete and integrated, tested and validated Oracle solution with all the software we mentioned and all the other hardware you need.
Big Data Appliance comes with Hadoop Cluster and Oracle Enterprise Linux installed. There is no relational database running on this product.
Oracle database components such as RAC, ASM are also not available. Instead, there is an Oracle NoSQL database that can store and query “Key-Value”.
Therefore, all software installed and running on Oracle Big Data Appliance is free. Oracle provides you with the environment to use Hadoop and what it can do right away.
Its setup is based on days, not weeks. Therefore, with Oracle Big Data Appliance, you will have left behind the process that I mentioned above, which took months and worked hard for you. You get the full support from Oracle.

The integrated software components of Oracle Big Data Appliance are as follows;
The hardware components of Oracle Big Data Appliance are as follows;
Oracle Big Data Appliance communicates with its own Infiniband (40 Gb/sec) network and communicates at least 4 times faster than any traditional architecture. It can also be fully integrated with other Oracle engineering systems.
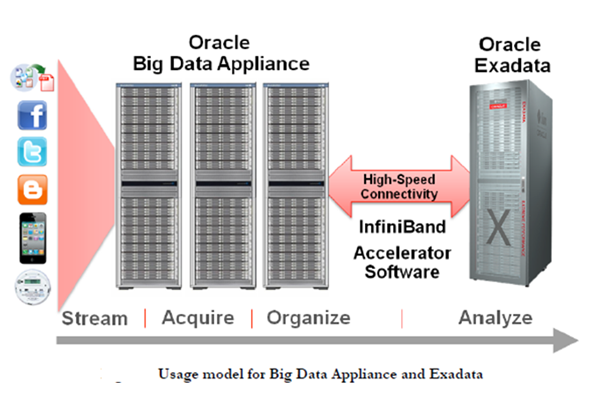
To summarize the above image from left to right, respectively;
Step 1 – Data Flow: It is the stage where different types of data from multiple sources flow into the system.
At this stage, the data flow to the system is prepared and configured to be uploaded to the Oracle Big Data Appliance.
Step 2 – Collecting and Organizing: Data is recorded and stored in high volume, diversity and speed in Oracle Big Data Appliance and hence HDFS.
By default, HDFS performs “triple mirroring” (stores incoming data in 3 copies) and distributes it over the installed Hadoop Cluster (18 nodes in total).
Step 3 – Analysis and Reporting: After passing the data on Oracle Big Data Appliance through a Java code we call “Map/Reduce” and bringing it into a format that can be uploaded to a relational database,
we transfer the data to Oracle Exadata, which we connect via Infiniband, and include it in the relational world.
At the beginning of my article, I stated that Big Data is limited by your imagination.
When you evaluate all these possibilities, you can see that there are many areas where you can use Big Data and its scope.
In addition, you can connect eight Big Data Appliances to each other via infiniband without the need for additional switches.
Another software developed and ready to use by Oracle is “Oracle Big Data Connectors”.
Oracle Big Data Connectors
The purpose of these software components is to easily extract data from Big Data Appliance to Oracle database.
In order to extract the data from HDFS and therefore from the Hadoop Cluster to the relational environment, you need to spend effort and time.
At the same time, you need to have qualified personnel in your institution or get consultancy services. Let’s talk about these connector software, which will act as a bridge between Big Data and Oracle database and reduce the installation effort and cost;
Oracle Loader for Hadoop
Oracle Direct Connector for Hadoop Distributed File System (HDFS)
Oracle Data Integrator Application Adapter for Hadoop
Oracle R Connector for Hadoop
Oracle Loader for Hadoop
This software is a kind of Map/Reduce tool and its purpose is to optimize the transfer of data from Hadoop to Oracle database.
Oracle Loader for Hadoop optimizes and modifies data so that it can be loaded into a format that can be loaded into the database.
In doing so, it also helps reduce the amount of possible CPU and I/O.
Oracle Direct Connector for Hadoop Distributed File System (HDFS)
The purpose of this software is to provide very fast access to HDFS media from Oracle database.
Thanks to the Direct Connector, we can query from the relational environment to the non-relational Big Data environment whenever we want.
I’m talking about direct SQL access here, a kind of “External Table”. Data on HDFS can be queried or loaded into a relational database.
Oracle Data Integrator Application Adapter for Hadoop
It is the software that combines ODI tool with Big Data. Its purpose is to transfer data to Oracle database over HDFS. Hadoop implementations require serious knowledge of Java and Map/Reduce code.
With the ODI Connector, Map/Reduce functions can be written and used with a graphical interface. Then, this developed code is run on Hadoop and Map/Reduce operations can be performed.
Oracle R Connector for Hadoop
R Connector allows us to perform statistical analysis.
![]()