 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
With SQL Server 2016, we are now able to use parallelism in the query using INSERT INTO… SELECT with WITH (TABLOCK).
In order for the query to run in parallel, the compatibility level of the database must be at least 130.
You may want to read the article “What is SQL Server Database Compatibility Level and How To Change Database Compatibility Level“.
Let’s examine how it works by making an example.
First, create the Person.Person table’s create script in the AdventureWorks database as follows.
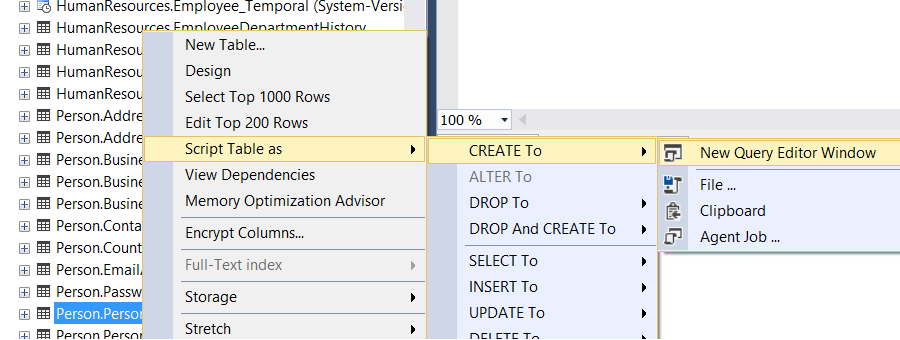
Then, using this script, let’s create a table named Person.Person2 with the same structure as Person.Person. Remember to change the table and constraint names before running the script. Otherwise you will receive errors like the following.
Msg 2714, Level 16, State 5, Line 27
There is already an object named ‘DF_Person_NameStyle’ in the database.
Msg 1750, Level 16, State 1, Line 27
Could not create constraint or index. See previous errors.
The script you will execute should be as follows.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | USE [AdventureWorks2016CTP3] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [Person].[Person2]( [BusinessEntityID] [int] NOT NULL, [PersonType] [nchar](2) NOT NULL, [NameStyle] [dbo].[NameStyle] NOT NULL, [Title] [nvarchar](8) NULL, [FirstName] [dbo].[Name] NOT NULL, [MiddleName] [dbo].[Name] NULL, [LastName] [dbo].[Name] NOT NULL, [Suffix] [nvarchar](10) NULL, [EmailPromotion] [int] NOT NULL, [AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL, [Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL, [rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL, [ModifiedDate] [datetime] NOT NULL, CONSTRAINT [PK_Person_BusinessEntityID_2] PRIMARY KEY CLUSTERED ( [BusinessEntityID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO ALTER TABLE [Person].[Person2] ADD CONSTRAINT [DF_Person_NameStyle2] DEFAULT ((0)) FOR [NameStyle] GO ALTER TABLE [Person].[Person2] ADD CONSTRAINT [DF_Person_EmailPromotion2] DEFAULT ((0)) FOR [EmailPromotion] GO ALTER TABLE [Person].[Person2] ADD CONSTRAINT [DF_Person_rowguid2] DEFAULT (newid()) FOR [rowguid] GO ALTER TABLE [Person].[Person2] ADD CONSTRAINT [DF_Person_ModifiedDate2] DEFAULT (getdate()) FOR [ModifiedDate] GO ALTER TABLE [Person].[Person2] WITH CHECK ADD CONSTRAINT [FK_Person_BusinessEntity_BusinessEntityID2] FOREIGN KEY([BusinessEntityID]) REFERENCES [Person].[BusinessEntity] ([BusinessEntityID]) GO ALTER TABLE [Person].[Person2] CHECK CONSTRAINT [FK_Person_BusinessEntity_BusinessEntityID2] GO ALTER TABLE [Person].[Person2] WITH CHECK ADD CONSTRAINT [CK_Person_EmailPromotion2] CHECK (([EmailPromotion]>=(0) AND [EmailPromotion]<=(2))) GO ALTER TABLE [Person].[Person2] CHECK CONSTRAINT [CK_Person_EmailPromotion2] GO ALTER TABLE [Person].[Person2] WITH CHECK ADD CONSTRAINT [CK_Person_PersonType2] CHECK (([PersonType] IS NULL OR (upper([PersonType])='GC' OR upper([PersonType])='SP' OR upper([PersonType])='EM' OR upper([PersonType])='IN' OR upper([PersonType])='VC' OR upper([PersonType])='SC'))) GO ALTER TABLE [Person].[Person2] CHECK CONSTRAINT [CK_Person_PersonType2] GO |
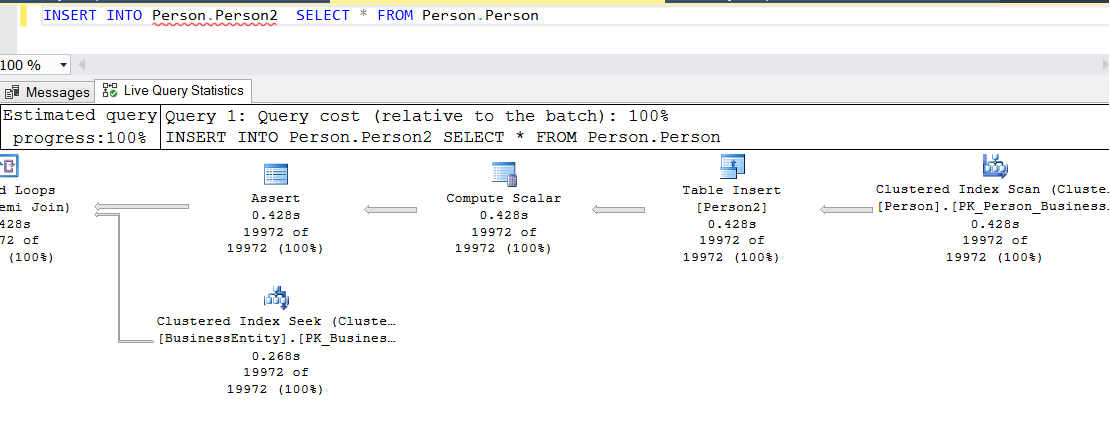
After creating the table, we remove the Primary Key from the Person2 table and run the insert into clause with the following script without parallelism.
1 | INSERT INTO Person.Person2 SELECT * FROM Person.Person |
When we look at the execution plan, we see that Clustered Index Scan and Table Insert operations are performed without parallelism.
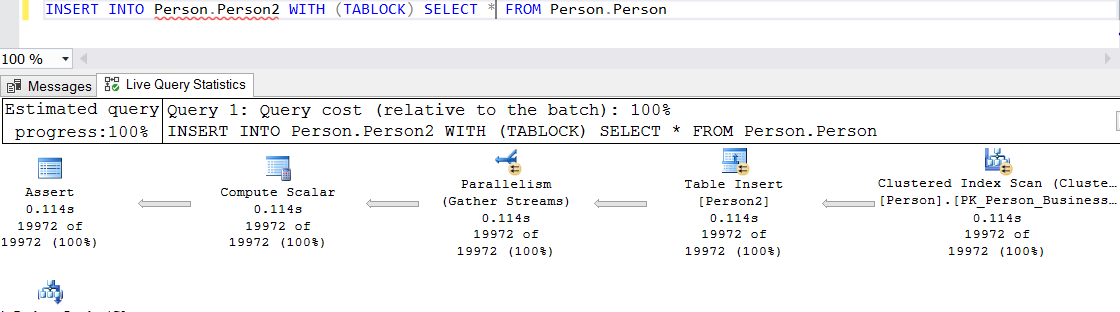
Execute the INSERT INTO statement with WITH (TABLOCK) as follows and look at the execution plan again.
As you can see the query worked this time using parallelism.
![]()