 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
This article contains information about table partitioning in PostgreSQL.
We will look at the answers for the questions;
- What is partition in PostgreSQL
- What are the advantages of Table Partitioning in PostgreSQL
- PostgreSQL Partition Types
What is Partition in PostgreSQL?
We will be discussing the table partitioning in PostgreSQL 11.2. The partitioning method used before PostgreSQL 10 was very manual and problematic. Imagine that before version 10, Trigger was used to transfer data to the corresponding partition. Imagine how old it is.
Partitioning the table according to certain criteria is called partitioning. The main table we partitioned is called master and each partition are called child.
What are the advantages of Table Partitioning in PostgreSQL?
- Improves query performance. (Since the queries read the data only from the relevant partition, query result will be faster.)
- Index cost and Size are decreasing. We reduce the size of our indexes and decrease the index fragmentation by creating an index in the relevant partition only.
- We will be able to manage our Bulk operations healthier and faster.
Partition Types in PostgreSQL
You can find the partition types in postgresql below.
LIST PARTITION in PostgreSQL
The table is partitioned according to the key value of the partition column. For Example, suppose that you have a table that contains person name and country information and you want to create a partition according to the country column’s value. You can perform this operation by using LIST PARTITION.
PostgreSQL List Partition Example
First execute the command \x for user friendly screen.
1 2 3 4 5 6 7 8 9 10 11 12 | CREATE TABLE person ( personname varchar(100), country varchar(100) ) PARTITION BY LIST(country); CREATE TABLE EUROPE PARTITION of person FOR VALUES IN('GERMANY','SPAIN'); CREATE TABLE ASIA PARTITION of person FOR VALUES IN('TURKEY','INDIA'); CREATE TABLE AFRICA PARTITION of person FOR VALUES IN('ANGOLA','BENIN'); CREATE TABLE NORTHAMERICA PARTITION of person FOR VALUES IN('US','MEXICO'); CREATE TABLE SOUTHAMERICA PARTITION of person FOR VALUES IN('ARGENTINA','ECUADOR'); CREATE TABLE AUSTRALIA PARTITION of person FOR VALUES IN('AUSTRALIA','FIJI'); |
Then check partitions created successfully; Write your table name instead of person in the below script if your table name is different.
1 2 3 4 5 6 | select pt.relname as partition_name, pg_get_expr(pt.relpartbound, pt.oid, true) as partition_expression from pg_class base_tb join pg_inherits i on i.inhparent = base_tb.oid join pg_class pt on pt.oid = i.inhrelid where base_tb.oid = 'public.person'::regclass; |
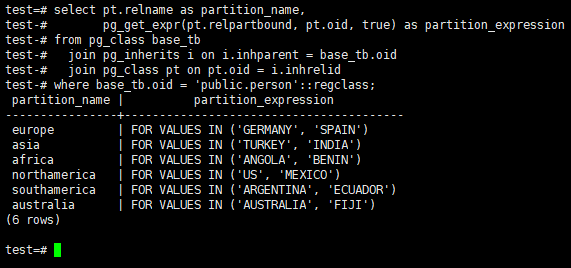
Insert new records to ASIA partition. The following data will be inserted to ASIA partition. Because the values TURKEY and INDIA is in the ASIA partition.
1 2 | INSERT INTO person VALUES ('Nurullah CAKIR', 'TURKEY'); INSERT INTO person VALUES ('Ahmad ANSAR', 'INDIA'); |
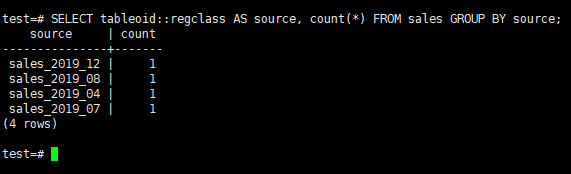
Get Row Count in Each Partititions
1 | SELECT tableoid::regclass AS source, count(*) FROM person GROUP BY source; |
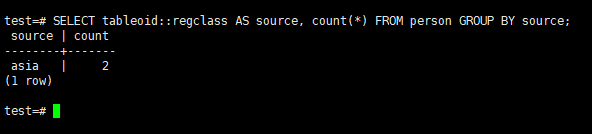
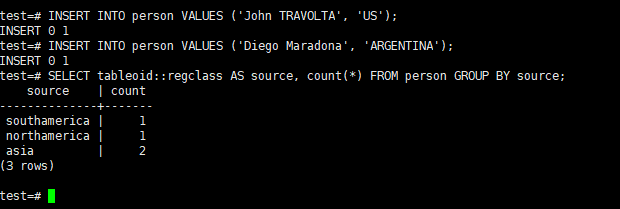
Then insert new records to other partitions to see the distribution.
1 2 | INSERT INTO person VALUES ('John TRAVOLTA', 'US'); INSERT INTO person VALUES ('Diego Maradona', 'ARGENTINA'); |
RANGE PARTITION in PostgreSQL
Table partitioning is performed according to a range according to the specified criteria. For example, we can create a range partition according to a specific date range, or we can create a range partition using a range according to other data types.
PostgreSQL Range Partition Example
Let’s create our demo table at first.
1 2 3 4 5 | CREATE TABLE sales ( id serial, sales_count int, sales_date date not null ) PARTITION BY RANGE (sales_date); |
We have specified partition type and partition column above. PARTITION BY RANGE (sales_date)
Now let’s create our Partitions. Since we will create partitions monthly, we divide our table into 12 for the last 1 year.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | CREATE TABLE sales_2019_01 PARTITION OF sales FOR VALUES FROM ('2019-01-01') TO ('2019-02-01'); CREATE TABLE sales_2019_02 PARTITION OF sales FOR VALUES FROM ('2019-02-01') TO ('2019-03-01'); CREATE TABLE sales_2019_03 PARTITION OF sales FOR VALUES FROM ('2019-03-01') TO ('2019-04-01'); CREATE TABLE sales_2019_04 PARTITION OF sales FOR VALUES FROM ('2019-04-01') TO ('2019-05-01'); CREATE TABLE sales_2019_05 PARTITION OF sales FOR VALUES FROM ('2019-05-01') TO ('2019-06-01'); CREATE TABLE sales_2019_06 PARTITION OF sales FOR VALUES FROM ('2019-06-01') TO ('2019-07-01'); CREATE TABLE sales_2019_07 PARTITION OF sales FOR VALUES FROM ('2019-07-01') TO ('2019-08-01'); CREATE TABLE sales_2019_08 PARTITION OF sales FOR VALUES FROM ('2019-08-01') TO ('2019-09-01'); CREATE TABLE sales_2019_09 PARTITION OF sales FOR VALUES FROM ('2019-09-01') TO ('2019-10-01'); CREATE TABLE sales_2019_10 PARTITION OF sales FOR VALUES FROM ('2019-10-01') TO ('2019-11-01'); CREATE TABLE sales_2019_11 PARTITION OF sales FOR VALUES FROM ('2019-11-01') TO ('2019-12-01'); CREATE TABLE sales_2019_12 PARTITION OF sales FOR VALUES FROM ('2019-12-01') TO ('2020-01-01'); |
Check Partitions in PostgreSQL
After creating our partitions, let’s have a chek without inserting data.
We can check the partitions we created with the help of the below script.
1 2 3 4 5 6 7 8 9 10 | SELECT nmsp_parent.nspname AS parent_schema, parent.relname AS parent, nmsp_child.nspname AS child_schema, child.relname AS child FROM pg_inherits JOIN pg_class parent ON pg_inherits.inhparent = parent.oid JOIN pg_class child ON pg_inherits.inhrelid = child.oid JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace WHERE parent.relname='sales' ; |
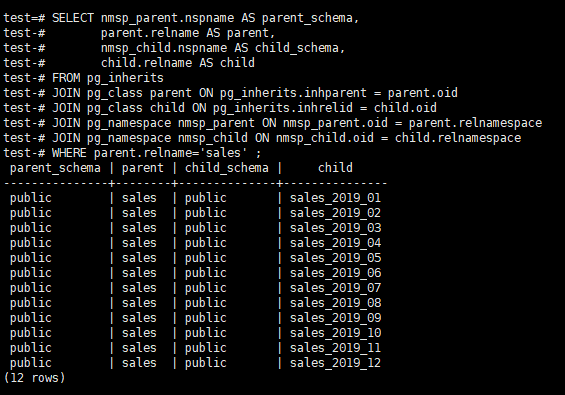
After completing our checks, let’s insert data to our table.
1 2 3 4 | INSERT INTO sales (sales_count, sales_date) VALUES (50 , '2019-04-12'); INSERT INTO sales (sales_count, sales_date) VALUES (80 , '2019-12-14'); INSERT INTO sales (sales_count, sales_date) VALUES (70 , '2019-07-15'); INSERT INTO sales (sales_count, sales_date) VALUES (75 , '2019-08-17'); |
Now let’s execute a query and check if our query brings data from the relevant partition.
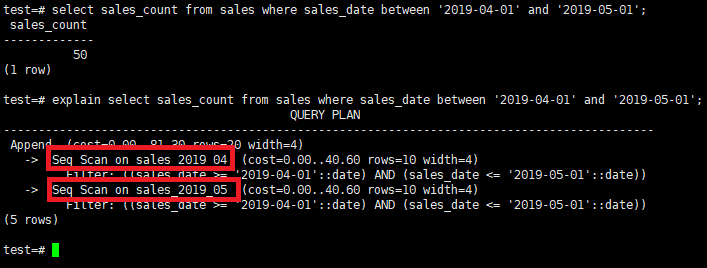
1 | select sales_count from sales where sales_date between '2019-04-01' and '2019-05-01'; |
Now let’s check which partitions it use with EXPLAIN.
1 | explain select sales_count from sales where sales_date between '2019-04-01' and '2019-05-01'; |
When you execute the query, we see that it uses the sales_2019_04 and sales_2019_05 partitions.
Get Row Count in Each Partition
1 | SELECT tableoid::regclass AS source, count(*) FROM person GROUP BY source; |
Hash PARTITION in PostgreSQL
In Hash Partition, data is transferred to partition tables according to the hash value of Partition Key(column you specified in PARTITION BY HASH statement). You can specify a single column or multiple columns when specifying the Partition Key. In order to distribute the data equally to partitions, you should take care that partition key is close to unique. It is created similar to the RANGE and LIST partition.
There are MODULUS and REMAINDER concepts during the creation of partitions tables. The MODULUS value indicates how many partition tables we have. It is fixed for all partition tables and does not change.
Since there are 10 partitions, REMAINDER can have a value from 0 to 9. If you do not specify the modulus and remainder values correctly, you will receive the below error.
ERROR: every hash partition modulus must be a factor of the next larger modulus
The hash value of the partition key used for the HASH partition is divided into MODULUS value and the data is transferred to the REMAINDER table pointed to by the remaining value.
For Example, suppose that the hash value is 102. It divides 102 by 10. Here, the remaining value is 2. So, the data will go to the REMANDER 2 table.
PostgreSQL Hash Partition Example
In this example, we will use the same table structure as the List Partition Example. But the partition column will be PersonName. But do not use name column as hash partition column in your production environment. Because names are often not unique. Therefore, data is not evenly distributed across partitions.
Note: Do not forget person table we have created for previous example.
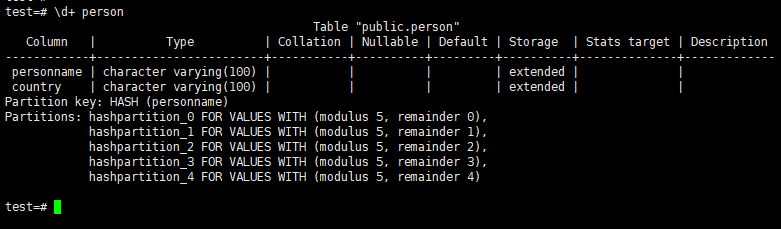
1 2 3 4 5 6 | CREATE TABLE person ( personname varchar(100), country varchar(100) ) PARTITION BY HASH(PersonName); |
1 2 3 4 5 | CREATE TABLE hashpartition_0 PARTITION OF person FOR VALUES WITH (MODULUS 5, REMAINDER 0); CREATE TABLE hashpartition_1 PARTITION OF person FOR VALUES WITH (MODULUS 5, REMAINDER 1); CREATE TABLE hashpartition_2 PARTITION OF person FOR VALUES WITH (MODULUS 5, REMAINDER 2); CREATE TABLE hashpartition_3 PARTITION OF person FOR VALUES WITH (MODULUS 5, REMAINDER 3); CREATE TABLE hashpartition_4 PARTITION OF person FOR VALUES WITH (MODULUS 5, REMAINDER 4); |
You can check partition is created with the command \d+ person
Insert Into data to the table. Note that we insert 3 row and the names of the 2 rows are the same. This will cause the data not to be evenly distributed across partition tables.
1 2 3 | INSERT INTO person (personname, country) VALUES ('Nurullah CAKIR', 'TURKEY'); INSERT INTO person (personname, country) VALUES ('Nurullah CAKIR', 'INDIA'); INSERT INTO person (personname, country) VALUES ('John TRAVOLTA', 'US'); |
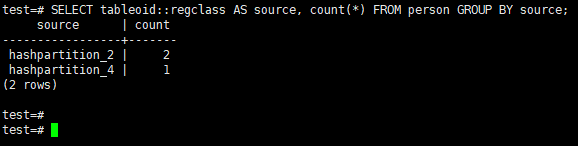
Select * from the main table and partition tables as below. You will see that there are no rows in the main table. Two rows will be on a partition because of two rows name value is the same and the other row will be in different partition.
1 2 3 4 5 6 | select * from only person; select * from only hashpartition_0; select * from only hashpartition_1; select * from only hashpartition_2; select * from only hashpartition_3; select * from only hashpartition_4; |
If you select maint table without only, you can see all the rows;
1 | select * from person; |
You can see the distribution with the below query;
1 | SELECT tableoid::regclass AS source, count(*) FROM person GROUP BY source; |
Sub-Partitioning in PostgreSQL
With Sub Partition, we can divide the partitions of the tables into sub-partitions. For example, suppose you have a partitioned table by years. It means a partition for each year. But you may also want to make partitions by months.
PostgreSQL Sub Partition Example
In this example, we will use the same table structure as the Range Partition Example.
Note: Do not forget sales table we have created for previous example.
1 2 3 4 5 | CREATE TABLE sales ( id serial, sales_count int, sales_date date not null ) PARTITION BY RANGE (sales_date); |
Create partition for 2018-2019-2020.
1 2 3 4 5 6 7 8 | CREATE TABLE sales_2018 PARTITION OF sales FOR VALUES FROM ('2018-01-01') TO ('2019-01-01'); CREATE TABLE sales_2019 PARTITION OF sales FOR VALUES FROM ('2019-01-01') TO ('2020-01-01'); CREATE TABLE sales_2020 PARTITION OF sales FOR VALUES FROM ('2020-01-01') TO ('2021-01-01'); |
Insert below records to table.
1 2 3 4 | INSERT INTO sales (sales_count, sales_date) VALUES (50 , '2018-04-12'); INSERT INTO sales (sales_count, sales_date) VALUES (80 , '2019-12-14'); INSERT INTO sales (sales_count, sales_date) VALUES (70 , '2020-01-01'); INSERT INTO sales (sales_count, sales_date) VALUES (75 , '2020-12-31'); |
Get Row Count in Each Partition
1 | SELECT tableoid::regclass AS source, count(*) FROM sales GROUP BY source; |
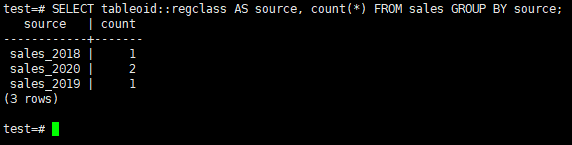
Suppose that your needs has changed and you need also sub partitions for new year. To perform this we will create a partition for sales_2021, and subpartitions for each month in 2021.
1 2 | create table sales_2021 partition of sales for values from ('2021-01-01') to ('2022-01-01') partition by range(sales_date); |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | create table sales_2021_01 partition of sales_2021 for values from ('2021-01-01') to ('2021-02-01'); create table sales_2021_02 partition of sales_2021 for values from ('2021-02-01') to ('2021-03-01'); create table sales_2021_03 partition of sales_2021 for values from ('2021-03-01') to ('2021-04-01'); create table sales_2021_04 partition of sales_2021 for values from ('2021-04-01') to ('2021-05-01'); create table sales_2021_05 partition of sales_2021 for values from ('2021-05-01') to ('2021-06-01'); create table sales_2021_06 partition of sales_2021 for values from ('2021-06-01') to ('2021-07-01'); create table sales_2021_07 partition of sales_2021 for values from ('2021-07-01') to ('2021-08-01'); create table sales_2021_08 partition of sales_2021 for values from ('2021-08-01') to ('2021-09-01'); create table sales_2021_09 partition of sales_2021 for values from ('2021-09-01') to ('2021-10-01'); create table sales_2021_10 partition of sales_2021 for values from ('2021-10-01') to ('2021-11-01'); create table sales_2021_11 partition of sales_2021 for values from ('2021-11-01') to ('2021-12-01'); create table sales_2021_12 partition of sales_2021 for values from ('2021-12-01') to ('2022-01-01'); |
The last partition structure of our table is as follows.
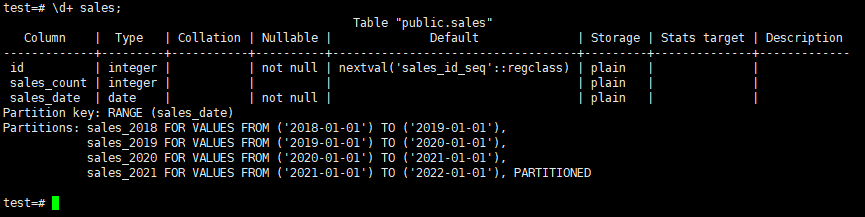
if you want to see the sub partitions you should execute the \d+ sales_2021 command.
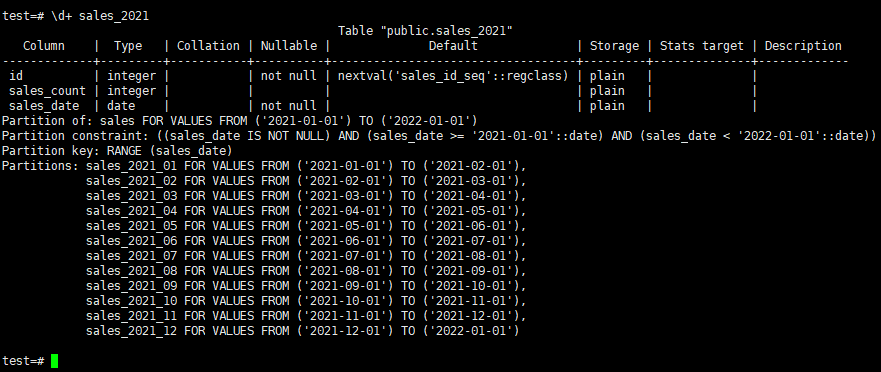
![]()
When I create a table without primary key, Postgres runs well with PARTITION BY RANGE(col_xyz). However, then I have a primary key, the message “unique constraint on partitioned table must include all partitioning columns.” Would you one please help show me how to do partition by range on table that have one or composite primary key? Thank you in advance for your explanation!