 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
If you are reading this article, you should read my articles “What is Primary Key And Foreign Key” and “What is Unique Constraint” at first.
After reading these articles, let’s examine the differences between primary key and unique constraint;
Difference Between Primary Key and Unique Constraint
Primary Key
- Primary Key can not contain null value.
- A table can only have one primary key.
- Sparse columns can not be used as part of the primary key. Sparse Column is perfect for your columns with a null value. If we define the column as sparse, null values dont take up space in the database. But if the null rate of the column is less, it will have the disadvantage to us. We can use Sparse Columns especially in filtered indexes. For example, if we create a filtered index by filtering non-null columns, we can provide a significant advantage. You can find the details in the article “What is Filtered Index in SQL Server“. You can mark the column as sparse from the IsSparce property in the table design stage.
- When you create a primary key on a column, a clustered index is created in this primary key column by default, and the table is physically sorted according to this column. You may want to read the article “Differences Between Clustered Index and Non Clustered Index“
- Primary Key can be related with another table’s Foreing Key.
- Auto-incrementing identity can be set. You may want to read the article “How To Set Identity Property to the Current Column in the Table“
Unique Constraint
- It can contain 1 Null value. Because 2nd Null value corrupts singularity. You will get an error like the following.
Violation of Unique Key Constraint ‘x’. Cannot insert duplicate key in object ‘x’.
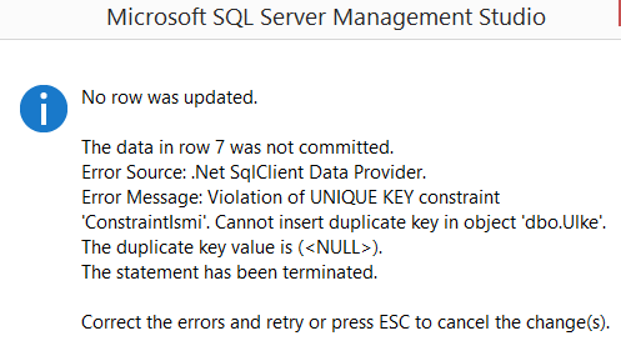
- Each table can have more than one Unique Constraint
- By default, if you create a unique constraint on a column, a nonclustered index created on that column by default.
- Auto-incrementing identity can not be set.
![]()