 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
The Filtered Index is a filtered nonclustered index. For example, you have 100,000 records in a table. And some of your queries are only interested in 20 thousand of these 100 thousand records. If you create nonclustered index in the table for these queries, this index will have 100 thousand records. But, since the query interested in only 20 thousand of 100 thousand records, it would be unnecessary to create an index of 100 thousand records. Here we see the filtered index. We can create an index for the recordset that the query will use, so that the query can run more efficiently.
Advantages of Filtered Index:
- Reduced storage usage with fewer records
- Because there are fewer records, the execution plan will be better quality. You can find details about the Execution Plan in the article “What is Execution Plan on SQL Server“.
Also, the filtered index will have filtered statistic. Filtered statistics will be more accurate than full-table statistics. You can find more detailed information in my article “Statistics Concept and Performance Effect on SQL Server” on statistics.
In summary, fewer records will be searched using a higher quality execution plan and a more accurate statistic. So there will be a serious performance increase.
- Maintenance will be easier as there are fewer records.
Let’s continue with an example of our article.
In our test database, we create a new table with the help of the following script and insert several records into this table.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | CREATE TABLE [dbo].[FilteredIndexExampleTable]( [ID] INT IDENTITY(1,1) NOT NULL, [Name] [varchar](50) NULL, [Surname] [varchar](50) NULL ) ON [PRIMARY] GO INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES('Nurullah','ÇAKIR') INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES('Hakan','GÜRBAŞLAR') INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES('Faruk','ERDEM') INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES(NULL,NULL) INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES(NULL,NULL) INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES(NULL,NULL) INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES(NULL,NULL) INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES(NULL,NULL) INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES(NULL,NULL) INSERT INTO [dbo].[FilteredIndexExampleTable]([Name],[Surname]) VALUES(NULL,NULL) |
As you can see in the script, we’ve added 10 records. There are some values in 3 of these 10 records. Other records have been inserted as null. Suppose we need to create index in Name and Surname columns. If we create nonclustered index, the number of records in this index will be as much as the number of records in the table. For more effective use, let’s create a filtered index that contains only non-null records for the Name and Surname columns.
1 2 3 | CREATE NONCLUSTERED INDEX NonNull_Name_Surname_FilteredIndex ON [dbo].[FilteredIndexExampleTable](Name, Surname) WHERE Name IS NOT NULL And Surname IS NOT NULL; |
In order to make a comparison, let’s create a nonclustered index without a filter.
1 2 | CREATE NONCLUSTERED INDEX Name_Surname ON [dbo].[FilteredIndexExampleTable](Name, Surname) |
Let’s check the number of records in nonclustered indexes in our table with the help of the following script.
1 2 3 4 | SELECT ind.name, dps.used_page_count, dps.row_count, ind.filter_definition FROM sys.dm_db_partition_stats dps INNER JOIN sys.indexes ind ON dps.object_id = ind.object_id AND dps.index_id = ind.index_id WHERE dps.object_id = OBJECT_ID('FilteredIndexExampleTable') and ind.type_desc='NONCLUSTERED' |
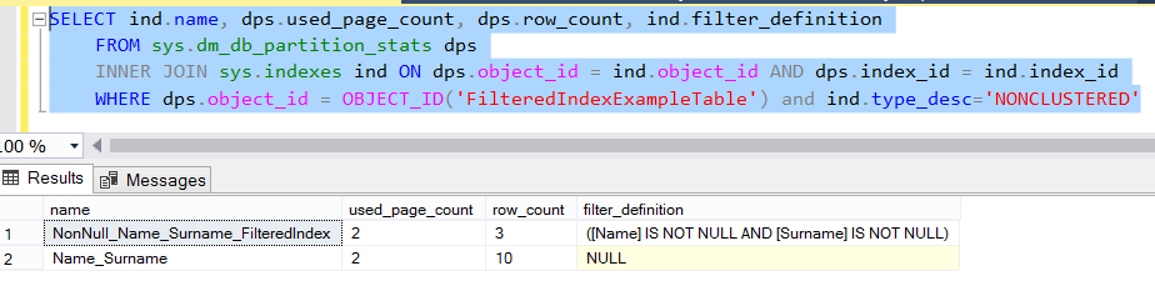
As you can see, there are 10 records in the normal nonclustered index named Name_Surname, and there are 3 records in the Filtered Index.
You can delete the filtered index using the following script.
1 | DROP INDEX [NonNull_Name_Surname_FilteredIndex] ON [dbo].[FilteredIndexExampleTable] |
![]()