 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
We will talk about SQL Server Statistics in this article.
What is Statistics in SQL Server?
When you execute a query on SQL Server, it decides how the query will work. It benefits from statistics when deciding how the query will work. The statistics shows the distribution of the data in the table or indexed views.
We mentioned how index will effect the performance of a query in the article “Index Concept and Performance Effect on SQL Server“.
Index Access Methods in SQL Server
SQL Server uses one or more of the following access methods to access data using statistics.
- It goes to the index and finds records that it searched for without searching all of the index(Index Seek)
- It goes to the index and finds records that it searched for with scanning all of the index(Index Scan)
- First it goes to the index and finds a column that it searched for without searching all of the index, then it goes to the clustered index with the key value on that index and finds the other columns of the record it is looking for. (Index Seek+Key Lookup)
- First it goes to the index and finds a column that it searched for with scanning all of the index, then it goes to the clustered index with the key value on that index and finds the other columns of the record it is looking for. (Index Scan+Key Lookup)
- It goes to the clustered index and finds records that it searched for without searching all of the clustered index (Clustered Index Seek)
- It goes to the clustered index and finds records that it searched for with scanning all of the clustered index (Clustered Index Scan)
For example, a table named Table1 would have 100 records.
This table has an index in column A. The value of 3 record is Tom and the value of the other 97 records is Jerry.
When I run the below query, SQL Server check the statistics and see Tom’s ratio as 3% on the table and it will decide that index seek is the fastest solution to execute the query.
1 | SELECT from Table1 where = 'Tom' |
1 | SELECT from Table1 where = 'Jerry' |
Since the distribution of Tom and Jerry values is different, using different query plan will be more efficient. So, if the SQL Server use the same query plan for Tom and Jerry, the query will not work with the correct execution plan each time and this will cause parameter sniffing.
I would recommend reading the articles named “Sp(Stored Procedure) On SQL Server” and “What is Parameter Sniffing“.
Let’s go back to the statistics
When we create an index, the statistics for that index are automatically created.
But if the index contains more than one column, only statistics for the first column are generated.
When we rebuild the index, the statistics are updated.
There are a few settings related to statistics on database basis.
Right-click on the database and select Properties, then select the Options tab.
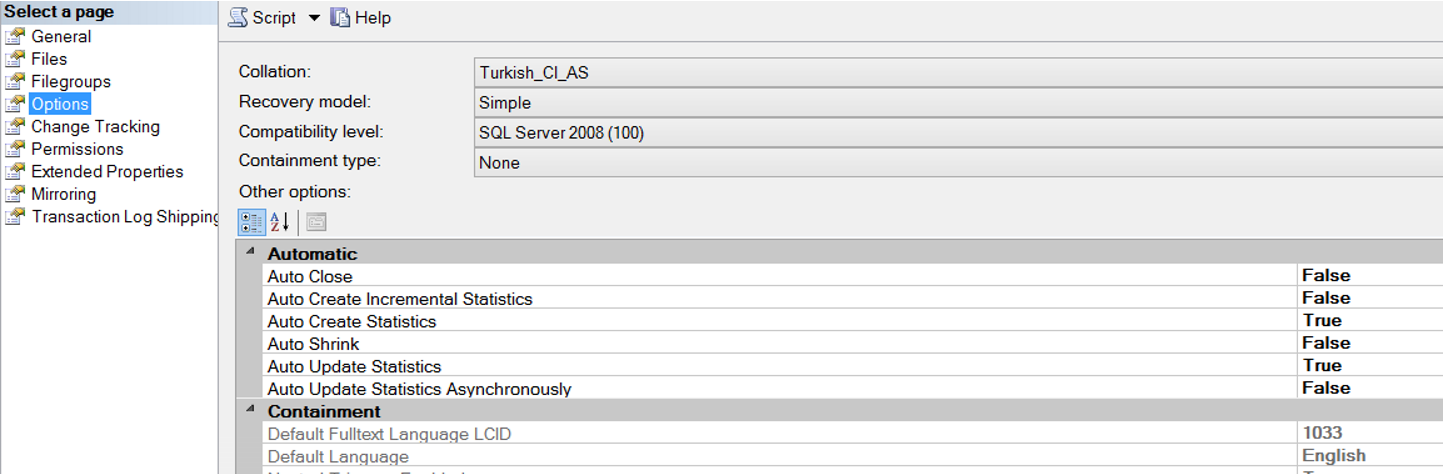
Statistic Settings in SQL Server
| Auto Create Statistics | If set to true and if there is no statistics on where clause of the query, the statistics will be created automayically on that column. Default is True. I would recommend you leave it like this. |
| Auto Update Statistics | If set to true, the statistic is automatically updated when the row change on the table exceeds 20%.When the change exceeds 20%, the first query to wait for the update of the statistic. Auto value is True. If there is no performance bottleneck on your system, it may remain True. If you set as False and you do not have a job that updates statistics, your system’s performance will gradually decrease because the statistics will be out of date. |
| Auto Update Statistics Asynchronously | Used with Auto Update Statistics feature.If you set as True, you will ensure that the update statistics operation works asynchronously and queries will not wait this operation. |
| Auto Create Incremental Statistics | It is a feature that introduced with SQL Server 2014.If your database has a partition, it can be very useful, if not , it is not needed. When you set Auto Update Statistics as True, the statistics are updated when the row change on the table exceeds 20%. And if you set Auto Create Incremental Statistics as True, it will be partition based. You can reduce the load on the system by updating statistic partition basis. I have not enabled this feature even in a database with a very busy transaction size of 20 TB. Because if you do not update statistics With FULLSCAN (I think it is not necessary), cost of updating statistics is not big for the system and it completing quickly. |
SQL Server Update Statistics Methods
There are two ways to update stats.
| sp_updatestats | Updates all statistics in the database. İt does not Update statistics With FULLSCAN. |
| UPDATE STATISTICS | You can update a specific statistic or all statistics of a table.The “Update Statistics dbo.myIdentity (ss)” command updates the ss statistics in the myIdentity table. The “Update Statistics dbo.myIdentity” command updates all statistics in the myIdentity table. The “Update Statistics dbo.myIdentity WITH FULLSCAN” command updates all statistics in the myIdentity table by scanning the entire table. If the table is big, it will take longer.. I have never used it until today. I do not think it’s necessary. |
UPDATE STATISTICS in SQL Server
The most important thing you need to know about statistics is that they have to be up to date.
In order to keep statistics up-to-date, you need to have a job that updates statistics except that settings I mentioned above.
I usually schedule update statistics job to work once a week, but on some systems the statistics can be out of date more quickly, and you may need to schedule the job to work once an hour. You should analyze the interval and schedule the job.
So if there is a performance problem in a system, the first thing we have to do is update the statistics.
I will share the script below which will update all statistics on all the databases on the Instance. You should create a job that contains this script and schedule according yo your system’s need.
If there is a database in restoring, read only or offline mode on the instance, the script will fail.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | DECLARE @SQL NVARCHAR(1000) DECLARE @DB sysname DECLARE curDB CURSOR FORWARD_ONLY STATIC FOR SELECT [name] FROM master..sysdatabases WHERE [name] NOT IN ('model', 'tempdb','master','msdb') ORDER BY [name] OPEN curDB FETCH NEXT FROM curDB INTO @DB WHILE @@FETCH_STATUS = 0 BEGIN IF DATABASEPROPERTYEX(@DB,'Updateability') = 'READ_WRITE' BEGIN SELECT @SQL = 'USE [' + @DB +']' + CHAR(13) + 'EXEC sp_updatestats' + CHAR(13) exec sp_executesql @SQL END FETCH NEXT FROM curDB INTO @DB END CLOSE curDB DEALLOCATE curDB |
![]()