 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
Being a DBA we have many hands-on experience and knowledge about replication. But replication is quite a bit different in case of Cassandra because it deals with a cluster that undergoes replication. So in this blog post,we are going to discuss the Replication factor and types of replication strategy that can be configured in a Cassandra cluster.Also, we have got a bonus tip at the end of the post.
Cassandra Data Replication:
Cassandra stores data as a replica in multiple nodes in a distributed format to ensure reliability and fault tolerance.It replicates rows in a column family on to multiple nodes based on the replication strategy associated with its keyspace.In general Cassandra stores only one copy of a given piece of data.
Replication factor(RF):
- Before deep diving into the replication strategies, let’s have a look at replication factor.
- It is the number of copies of data to be stored in a cluster.
- Cassandra will achieve high consistency when the read replica count plus the write replica count is greater than the replication factor. In order to guarantee the consistency in the cluster an optimal value should be set for RF. The value of RF should not exceed the number of nodes in the cluster.
Replica strategy:
It determines how data is written and read from Cassandra.
Data present in all replica are equally important there are no primary or secondary nodes. Below are the types of replica strategy:
- Simple Strategy(Rack-Unaware)
- Network topology Strategy (Rack-Aware)
Simple Strategy:
This strategy treats the entire cluster as a single data center. Suitable for a single data center and one rack.This is also called as Rack-Unaware Strategy.

Network topology Strategy:
Network strategy is used to specify data centers and the number of replicas to place within each data center. It attempts to place replicas on distinct racks to avoid the node failure and to ensure data availability.
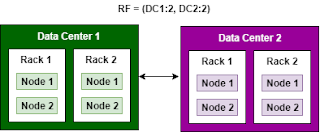
Note:Also if you are planning to expand the cluster in the future to have more than one data center then choosing NetworkTopologyStategy from the beginning avoids data migration.
And the bonus tip seeks in now.
Increasing Replication factor:
In a cluster replication factor is not a parameter that needs to be changed often on a live cluster it should be figured ahead of time. But in course of time as our application grows we will have to add some nodes to the cluster which crumbles the replication factor config in a cluster. So whenever we change the RF in a cluster we will have to restart the nodes to apply the new changes. After the restart, the Cassandra cluster will perform some repair process to redistribute data among the nodes in the cluster. In the intervening time, we will face some issues when connecting from the application where the nodes will not be able to serve the requested data.
So that’s it hope you must have got a few insight about replication in Cassandra. If you have any queries regarding the replication in Cassandra throw your comments.
![]()