 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
We are able to configure some critical options set at instance level, such as MAXDOP, at the database level with Database Scoped Configurations feature of SQL Server 2016. Especially on consolidated systems, you may need to configure the databases differently. In this sense, I think this is a very nice development.
At the database level we are able to configure the following options. You can access Database Scoped Configurations by right-clicking on the database, clicking properties, and then clicking on the Options tab.
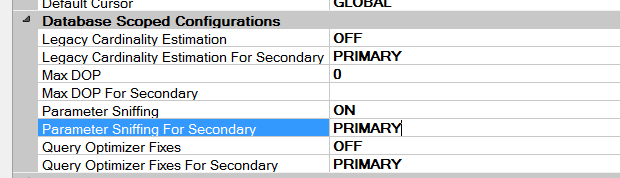
Features Supported by Database Scoped Configurations
Legacy Cardinality Estimation
In SQL Server 2014, Cardinality Estimator has been redesigned. New version of Cardinality Estimator allows better query plan generation by predicting how many rows the query will return. In order for queries to use the new cardinality estimator, the Compatibility Level must be 120 or higher.
A better query plan is produced with new cardinality estimator for 98% of the queries. But for a 2% slice, Legacy CE has the opposite effect. In such cases, you can downgrade the compatibility level to 110. But you’ll be deprived of the many improvements that the new compatibility level provide.
Or, instead of downgrade the compatibility level, you can use the old cardinality estimator for the database with the help of the following script. The default value is OFF, and if the compatibility level is 120 or higher, it uses the new cardinality estimator.
Enable Legacy Cardinality Estimation
1 | ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION=ON; |
1 | OPTION (USE HINT ('FORCE_LEGACY_CARDINALITY_ESTIMATION')); |
1 | ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET LEGACY_CARDINALITY_ESTIMATION=PRIMARY ; |
1 | ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET LEGACY_CARDINALITY_ESTIMATION=OFF; |
MAX DOP
We could previously set the maxdop value of the queries at the instance or query level. We can now set specific MAXDOP values for specific databases. To understand MAXDOP, you can read “Numa Nodes, MAX / MIN Server Memory, Lock Pages In Memory, MAXDOP“.
The configuration at the database level overrides the configuration at the instance level. If a session level maxdop is set, it will override the database level.
We can set maxdop at database level with the help of the following query.
1 | ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP =1 ; |
If you are using Always On Availability Group, you can set a different maxdop setting for your seconday database as follows.
1 | ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET MAXDOP=4 ; |
Also, you can configure your secondary database to use the same max dop setting as the primary database with the following query.
1 | ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET MAXDOP=PRIMARY; |
Parameter Sniffing
To understand what this database scoped configuration is, we must first understand what parameter sniffing is. You can find a detailed content in the article “What is Parameter Sniffing”.
You can use the following script to solve the parameter sniffing problem for the database. When you execute this script, all queries act as if “OPTIMIZE FOR UNKNOWN” has been added at the end of each query in the database.
1 | ALTER DATABASE SCOPED CONFIGURATION SET PARAMETER_SNIFFING =OFF; |
If you use always on availability group, you can prevent the parameter sniffing problem in the secondary database with the help of the below script.
1 | ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET PARAMETER_SNIFFING=OFF; |
Also, you can configure your secondary database to use the parameter sniffing setting as the primary database with the following query.
1 | ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET PARAMETER_SNIFFING=PRIMARY; |
Query Optimizer Fixes
By enabling this configuration, we set it up to take advantage of the latest hotfixes related to Query Optimizer, regardless of the compatibility level of the database.
We can enable it as follows.
1 | ALTER DATABASE SCOPED CONFIGURATION SET QUERY_OPTIMIZER_HOTFIXES=ON; |
You can configure your secondary database to use the same setting as the primary database with the following query.
1 | ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET QUERY_OPTIMIZER_HOTFIXES =PRIMARY; |
Clear Procedure Cache
You can use this database scoped configuration to clear the procedure cache in the database. You can perform this operation with the following script.
1 | ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; |
Identitiy Cache
This is database scoped configuration announced with SQL Server 2017.
It would be better to explain this configuration through a scenario.
Suppose that you have an auto increment identity column in a table;
If the service closes unexpectedly before commit while inserting data into this table, or if the failover occurs, there will be gaps on the auto increment identity values.
For example, you have inserted 5 records. ID values 1,2,3,4,5. Subsequent inserts should continue as 6,7,8. But it continues from 1003,1004 after the service closes unexpectedly. We can solve this problem by disabling Identity cache with the following script.
Disable Identitiy Cache
1 | ALTER DATABASE SCOPED CONFIGURATION SET IDENTITY_CACHE=OFF ; |
Check Current Database Scoped Configurations
1 | select * from sys.database_scoped_configurations |
![]()