 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
In today’s article, we will be learning about Oracle Data Pump Architecture.
It has 4 important components.
-expdp (export data pump)
-impdp (import data pump)
-DBMS_DATAPUMP (Oracle’s internal package)
-DBMS_METADATA (Oracle’s internal package)
Expdp and impdp tools use DBMS_DATAPUMP and DBMS_METADATA packages in the background
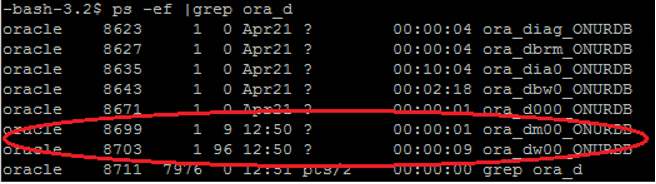
When we start the export/import process with Data Pump, a process called ora_dmNN_<DatabaseSID> is started on the server where our database is located.
This process acts as the master process.
Worker processes are activated depending on the processing load and parallelism.
Worker processes work depending on the master process.
Worker processes run on the server where our database is located, with the name ora_dw_NN_<DatabaseSID>.
During the export process, we can see the processes starting with ora_dm and ora_dw in the linux operating system processes on which our database is running.
1 | # ps -ef | grep ora_d |
When a user initiates an export or import operation with Data Pump, a status table is created under his own schema.
The name of this table is SYS_OPERATION_<JOB_MODU>_NN.
Here;
TRANSACTION: Indicates what the transaction (export or import) is.
JOB_MODU: Specifies whether the size of the data to be moved is full (all data), schema, table or tablespace.
NN: A number generated so that the table name of the same transactions started at the same time as the user is unique.
With this table, we can access detailed data about exported/imported data.
The status table is automatically deleted when the Data Pump operation is successful.
If the Data Pump process terminates incorrectly, the table is not automatically deleted. In this way, the table is checked and errors are seen.
Data Pump uses the database directory schema object to write to the dump file during export and to read the dump file during import.
We need to specify which database directory to use when defining the export/import operation on the command line.
If not specified, the database directory is used by default.
![]()