 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
Before you start reading this article, I suggest you read the article “Index Concept and Performance Effect on SQL Server” for more detailed information about indexes.
If you have queries that join the two tables on the same column, you should create indexes on the join columns. For example, in the AdventureWorks2014 database, let’s take a look at the execution plan of the following query.
To take the Execution Plan, you must click on the following black frame in the query screen on the SSMS. For detailed information about the Execution plan, please read the article “What is Execution Plan On SQL Server“.
1 2 3 4 5 | SELECT DISTINCT P.ProductID, P.Name FROM Sales.SalesOrderDetail AS SOD JOIN Production.Product AS P ON SOD.ProductID = p.ProductID WHERE P.ProductID = 707; |
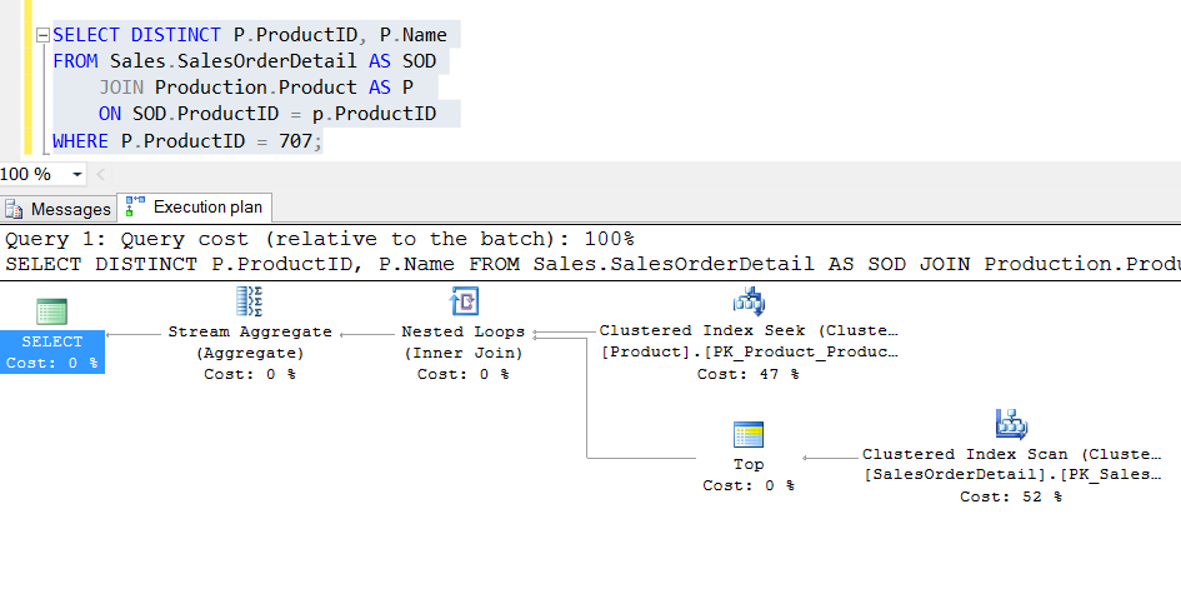
If you take the execution plan for the above query in the AdventureWorks database, the result may not appear as above. First, you must delete the index that is created on the ProductID in the SalesOrderDetail table, and then take the execution plan again.
As seen in the Execution plan, the Clustered Index Scan process has been performed despite reading a single record for the SalesOrderDetail table. Because there is no index on the join column. I have deleted the index above to show the importance of having index on the Join column.
Now re-create the index as below and take the query’s execution plan again.
1 2 3 4 5 | CREATE NONCLUSTERED INDEX [IX_ProductID] ON [Sales].[SalesOrderDetail] ( [ProductID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = ON, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) |
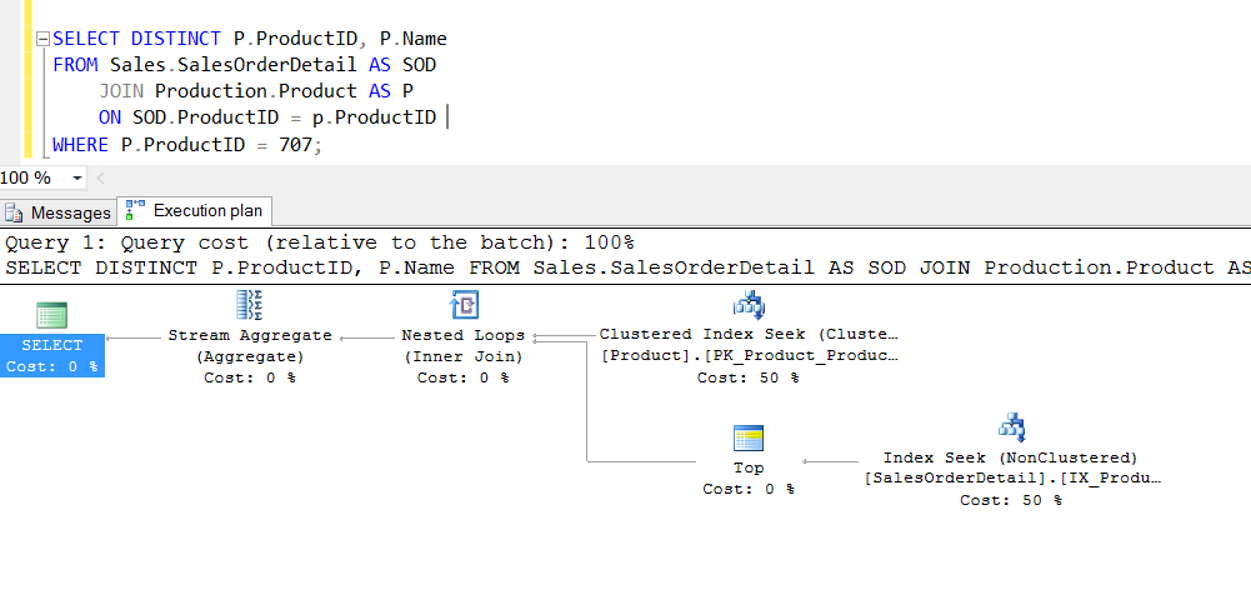
As you can see, the Clustered Index Scan process has returned to Index Seek.
You may want to read the article “Statistic Concept and Performance Effect on SQL Server” to learn more about what is “Clustered Index Scan” and “Index Seek”.
![]()