 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
Before you start reading this article, I suggest you read the article “Index Concept and Performance Effect on SQL Server” for more detailed information about indexes.
If there is no index in the Order By column, the query will sort the result set, and there will also be a sort cost. In addition, if we want to create the index for the Order By column, the most important thing is how the column is sorted.
I’ll go through an example to make it easier to understand.
We will do our tests in the AdventureWorks2014 database.
First, let’s take a look at the execution plan of the following query as shown in the picture below.
1 2 3 4 5 | SELECT RejectedQty, ((RejectedQty/OrderQty)*100) AS RejectionRate, ProductID, DueDate FROM Purchasing.PurchaseOrderDetail where ProductID between 100 AND 1000 ORDER BY RejectedQty DESC, ProductID ASC; |
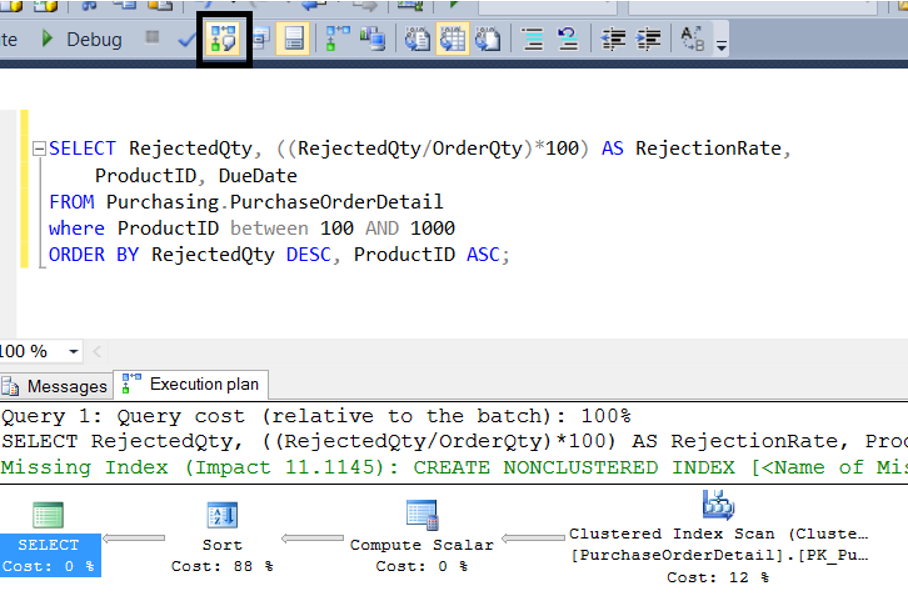
As you can see, most of the cost of the query is a sort operation. Let’s create an index that will cover the query as below, and look at the execution plan again.
1 2 3 | CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty ON Purchasing.PurchaseOrderDetail (RejectedQty ASC, ProductID ASC, DueDate, OrderQty); |
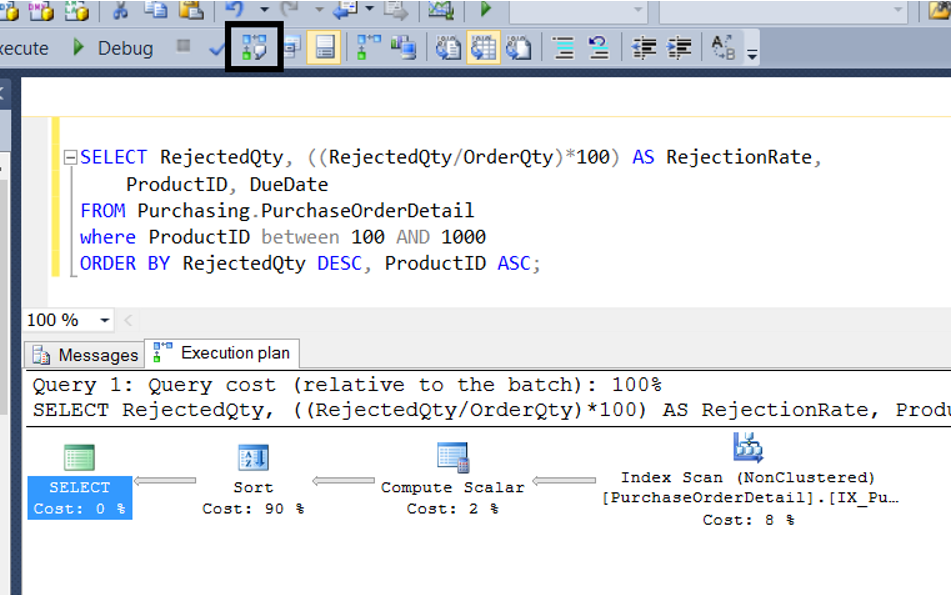
The query used the index we created, but the sort operation is still a large part of the cost. The reason for this is that the index that we created is sorted with ASC, but this column is sorted with DESC in the query.
Now let’s create the index with a different name by simply converting the ASC to DESC.
1 2 3 | CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQtyWITHDESC ON Purchasing.PurchaseOrderDetail (RejectedQty DESC, ProductID ASC, DueDate, OrderQty); |
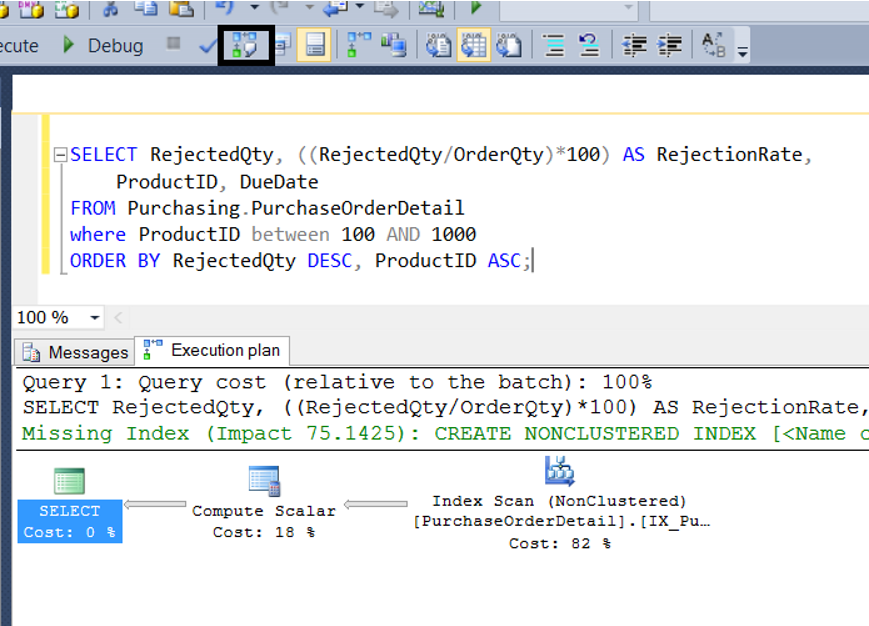
As you can see, we just recreated the index by changing the index’s sorting, and the cost of the query fell dramatically. The cost of Index SCAN increases from 8% to 82%. It shows how much the total cost of this query is reduced. We also no longer see the cost of the sort operation in the query. Because the index is sorted correctly. So there is no need for reordering.
![]()