 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
What is PolyBase?
This article contains information about PolyBase in sql server. Use cases, installation steps,configuring polybase cluster.
With PolyBase;
- We can bridge between SQL Server and Hadoop, PDW, Azure Blob Storage, or Azure Data Lake Store.
- We can access SQL Server from the above mentioned environments outside of SQL Server using TSQL.
- With SQL Server 2019, we can now use Polybase to access Oracle, Teradata and MongoDB.
With the use of different technologies according to the need, we need to query both relational and non-relational data at the same time. Polybase is a bridge between these two types of systems.
PolyBase Use Cases
- We can query the data on Hadoop using TSQL over SQL Server or PDW.
- We can query the data on Azure Blob Storage using TSQL over SQL Server.
- We can import data to SQL Server through Hadoop, Azure Blob Storage, or Azure Data Lake Store.
- We can export data from SQL Server to Hadoop, Azure Blob Storage, or Azure Data Lake Store.
- We can use PolyBase with third party tools supported by Microsft BI or SQL Server.
- We can use PolyBase to access Oracle,Teradata or MongoDB
PolyBase Installation Requirements
To install PolyBase, your server must have the following components.
- 64-bit SQL Server Instance
- Microsoft .NET Framework 4.5
- Oracle Java SE RunTime Environment (JRE) (at least version 7.51)
- Minimum 4 GB memory
- Minimum 2 GB disk
- The TCP / IP protocol must be enabled. You can find the required information in the article “SQL Server Configuration Manager Settings“.
- Systems such as Azure, HADOOP. Because we will use PolyBase with SQL Server and other external systems.
Install PolyBase
During SQL Server Installation, we need to select PolyBase Query Service for External Data in the Feature Selection screen as follows. For detailed information about the installation, please read the article “How To Install SQL Server“.
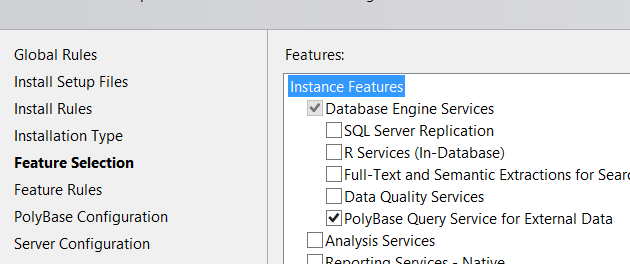
After the above screen, we see a screen like the one below.
Use this SQL Server as standalone PolyBase-enabled instance:
This means that we have selected SQL Server Intance as the Standalone head node. This means that we will process the data read from Hadoop on a single instance.
Use this SQL Server as a part of PolyBase scale-out group:
We may experience performance problems when processing large data on a single instance. By selecting this option, we select the instance we are installing as a Compute node in a cluster of SQL Server Instances to process large data with PolyBase Group feature.
If your organization has a firewall, you will need to open the ports specified in the following screenshot among all nodes in the PolyBase scale-out group. Here you can also specify the port range yourself. The port range you specify must be minimum 6. Even if it is more than 6, SQL Server will use the first 6 ports during the installation.
The following screenshot from Microsoft’s website summarizes the situation very well.
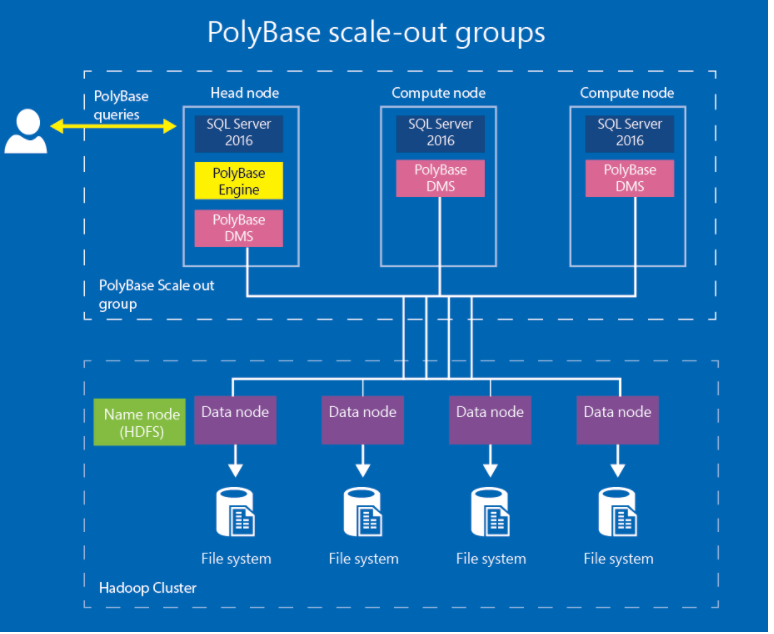
You can see the options mentioned above in the screenshot below.
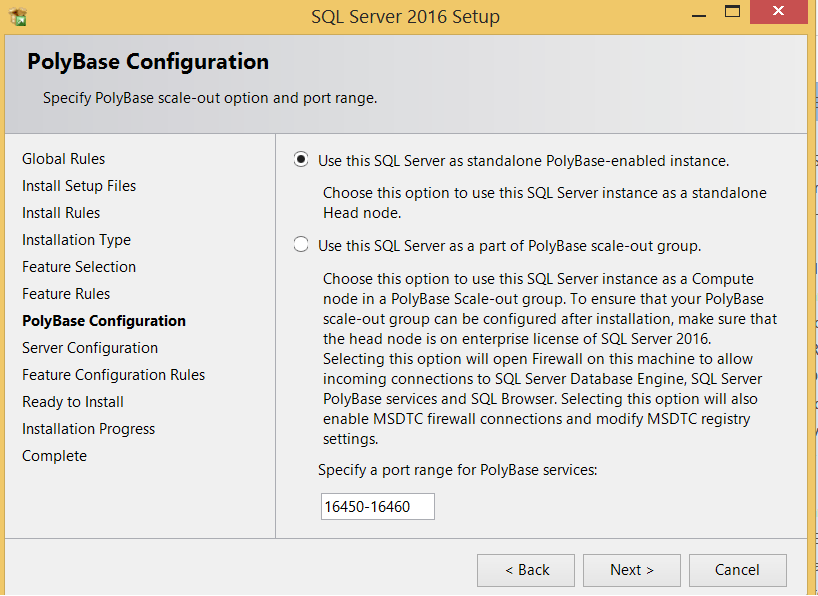
On the next screen, the Server Configuration screen, we need to specify accounts for the SQL Server PolyBase Engine and SQL Server PolyBase Data Movement services.
If we use the PolyBase scale-out group in the second option above, the PolyBase engine and PolyBase data movement services on all nodes must use the same domain account.
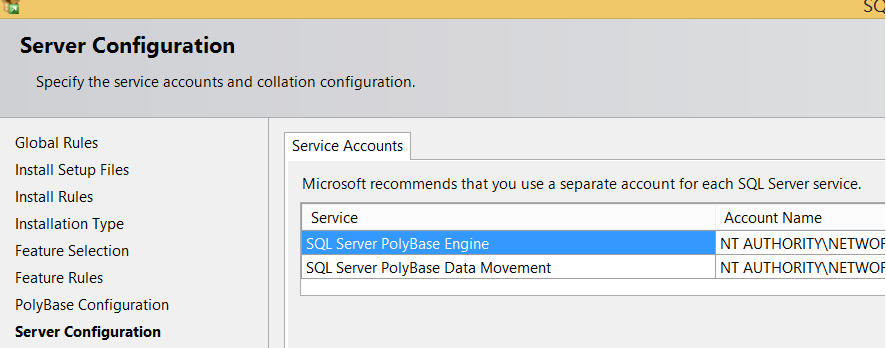
Click Next, Next and Finish to complete the installation.
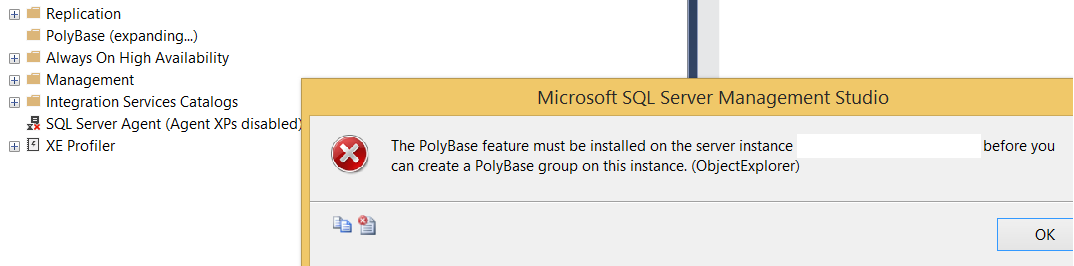
If PolyBase is not installed on Instance, clicking on the + sign on PolyBase via SSMS will throw an error as follows.
The PolyBase feature must be installed on the server instance before you can create a PolyBase group on this instance.
After the installation is complete, you must configure SQL Server to connect to external sources such as Azure, HADOOP.
With the following command, you can configure as follows to connect to Azure Blob Storage. By default, this setting is 7 after installation. You can set one of the following options for another connection type.
1 2 3 4 | sp_configure 'hadoop connectivity',7 GO RECONFIGURE GO |
Option 0: Disable Hadoop connectivity
Option 1: Hortonworks HDP 1.3 on Windows Server
Option 1: Azure blob storage (WASB[S])
Option 2: Hortonworks HDP 1.3 on Linux
Option 3: Cloudera CDH 4.3 on Linux
Option 4: Hortonworks HDP 2.0 on Windows Server
Option 4: Azure blob storage (WASB[S])
Option 5: Hortonworks HDP 2.0 on Linux
Option 6: Cloudera 5.1, 5.2, 5.3, 5.4, 5.5, 5.9, 5.10, 5.11, 5.12, and 5.13 on Linux
Option 7: Hortonworks 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 3.0 on Linux
Option 7: Hortonworks 2.1, 2.2, and 2.3 on Windows Server
Option 7: Azure blob storage (WASB[S])
To improve performance, copy the value of the yarn.application.classpath configuration key in the yarn-site.xml file in the HADOOP configuration directory and paste to yarn.application.classpath property in the yarn-site.xml.
Configure PolyBase Cluster
You can configure polybase cluster after installation as below.
You will see a screen like the one below. You can add the desired instances to this group by clicking the + sign.
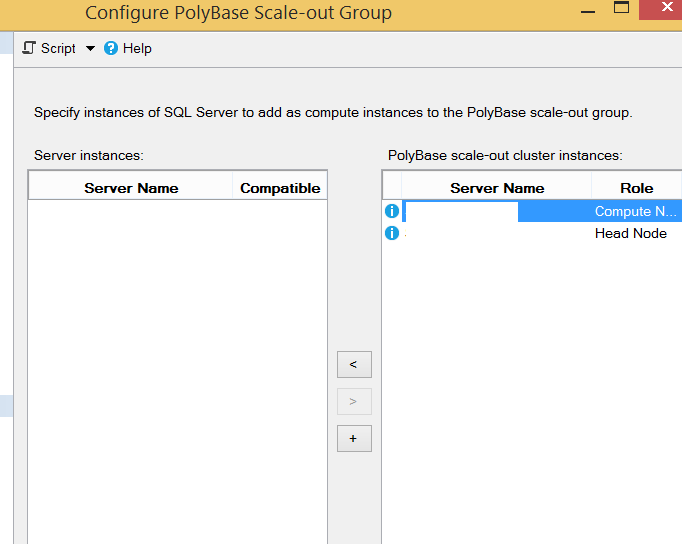
After defining the head node after installation, we can set other nodes as compute nodes.
— head node server name, head node dms control channel port, head node sql server instance name
1 | EXEC sp_polybase_join_group 'MyServer', 16450, 'MSSQLSERVER'; |
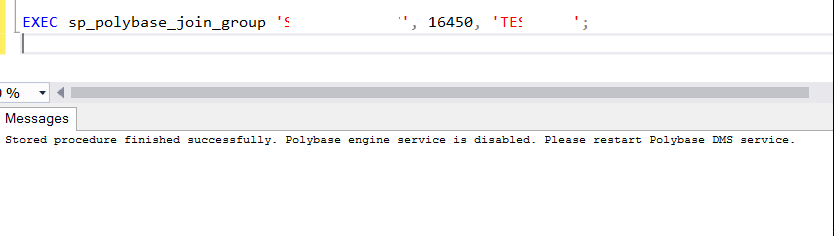
After performing these operations, disable PolyBase Engine Service and restart Data Movement Service on Compute Nodes.
Remove a Compute Node From PolyBase Cluster
You can remove a compute node from the cluster with the following script.
1 | EXEC sp_polybase_leave_group; |
Note: SQL Server installed in Head Node must be Enterprise Edition.
You can also transfer data between Azure or Hadoop and SQL Server using the links below.
https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-t-sql-objects
https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-queries
![]()