 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
To better understand this article, I would first recommend reading the “Index Concept and Performance Effect on SQL Server” and “Statistics Concept and Performance Effect on SQL Server” articles.
In these two articles, the concepts of Index and statistics are explained in detail.
Differences Between Clustered Index and Non Clustered Index
| Clustered Index | Non Clustered Index |
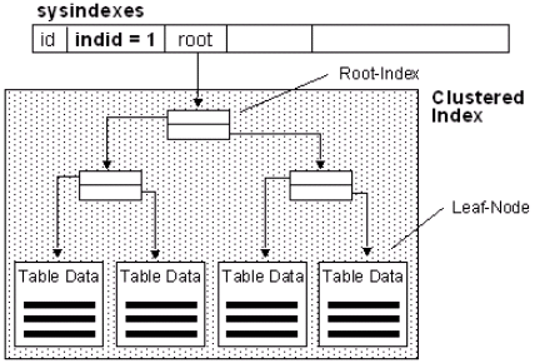 | 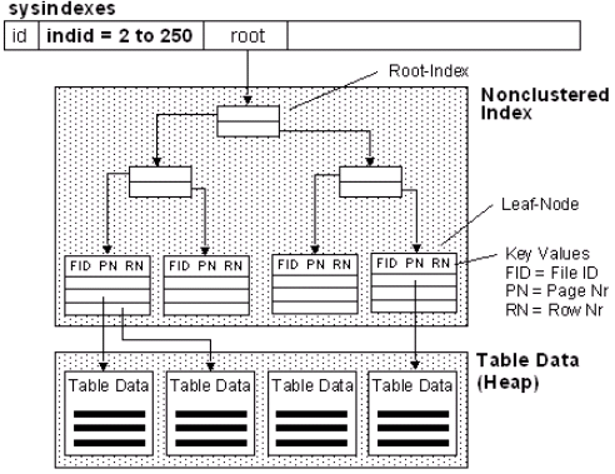 |
The data (table) is stored logically ordered according to the clustered index on the disk. | Non-clustered indexes are stored separately on the disk independently of the table.So, there you need extra disk space. If there are too many nonclustered indexes in the table, insert, update and delete performance will slow down because each insert, update and delete operation will be applied to all nonclustered indexes in this table. So it is not always a good thing to create too many nonclustered indexes. |
| While we select the data, when we reach the Leaf Level of the index, we reach the data. To understand Leaf Level concept -> “Index Concept and Performance Effect On SQL Server“ | While we select the data, when we reach the Leaf Level of the non clustered index, we reach the Row Locator instead of the data.If the table is heap, there is Row ID (RID) as row locator in the Leaf Level. This RID used to reach the requested data set. This process is called as RID Lookup. It’s not a good thing. Be sure to create a clustered index on your table. If the table is not heap, there is Clustered Index Key as row locator in the Leaf Level. This Clustered Index Key used to reach the requested data set. This process is called Key Lookup. |
| A table can have one clustered index(because the whole table is stored logically ordered in the disk according to the clustered index, the table can only be stored ordered by one clustered index). | The table is not sorted by nonclustered index, and the nonclustered index is stored separate from the table. Therefore, a table can have more than one non clustered index. |
| You can not add included column to the clustered index. Because there is the data itself in the Leaf Level. | You can add Included Column to the non clustered index. I have explained the included column in detail in the article “Index Concept in SQL Server and Performance Impact“ |
| It can be Unique or non-unique. If it is non-unique (which I do not recommend), sql server put a 4-byte identifier named uniqueifier to make the clustered index keys unique. This ensures that a query using a nonclustered index finds the data that it needs. Extra cost, extra size. | It can be unique or non unique.If it is unique, queries will return faster results. For example, we have 100 records in our table. You will create an index and 100 of the 100 records in the column are different from each other. If you search for one, you can find it directly. This process is called index seek. But if the values of 70 of the 100 records in the column are the same as each other, all of the records in this index will be scan and then you can find what you need. This process is called index scan. It looks bad, but in some cases it is better than scanning the entire table. (Table scan) So, if its possible, use unique columns for creating indexes. |
Conclusion
Clearly, Clustered Index and Non-Clustered Index are not alternative index types.
A table must have a clustered index. If there is no clustered index, the table will be scattered on the disk.
You can create non clustered index for searching another column except the clustered index column on a table that has a clustered index.
In addition, you may need to use a primary key foreign key because you are using a relational database.
If you create a primary key on the table, sql server automatically create a clustered index on the column where you create the primary key.
Even if SQL Server creates a clustered index by default, you can force the primary key column to be nonclustered.
For primary key and foreign key concepts, you can read the following articles.
“What is Primary Key and Foreign Key“,
“Differences Between Primary Key and Unique Constraint”
![]()
Good job
Thank you