 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
When choosing a RAID structure or designing storage, I strongly recommend that you do not stay away. These processes directly affect database performance. The storage specialist in your organization cannot know your read and write rate or what application needs more IO. So you need to give him some parameters when requesting the disk. In order to provide these parameters, you must know the RAID structure and how storage works in the background. Consider these issues as far as a DBA needs to know.
Before reading this article, I would recommend you to read my articles named “The SAN Infrastructure That SQL Server Uses, and the Story of a Query” ve “How To Calculate IOPS and Throughput of Your Database Server Using Data Collector”
RAID(Redundant Array of Independent Disk Drives):
It is the technology that enables disks to work more efficiently and / or safer (against data loss). There are various types of RAID.
While performance is good at some RAID levels, it is more likely to lose data.
Some RAID levels are less likely to lose data while performance is worse.
At some RAID levels, both performance is high and data loss is less likely.
As the RAID level changes, the number of disks used will change. Naturally the cost will change.
Now let’s talk about the most common types of RAID.
RAID 0:
It is very fast in terms of performance but it is more likely to lose data. Can be created with at least two disks. Data is split and written to the disks at the same time, and these split parts are read from different disks simultaneously.
It is not necessary to use an extra disk to create this structure. For example, for 2 TB of data, 1 TB of two disks will suffice. 2 TB data will be written to 2 disks with a size of 1 TB. Not used on Mission Critical systems. It can be used in systems where data loss is not important and performance is important. The following figure shows the structure of RAID 0.
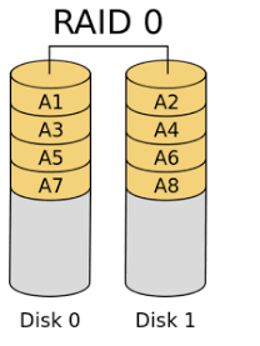
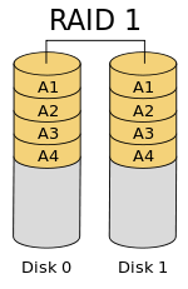
RAID 1:
It is slow in terms of performance but less likely to lose data. It can be created with at least two disks. Writes the data to 2 disks in copies. That’s why the cost of the disk is doubled.
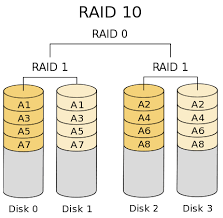
RAID 10:
It can be created with at least 4 disks. As its name implies, it is a mixture of RAID 0 and RAID 1. It is created by combining two RAID 1 groups into RAID 0. Disk cost is as in RAID 1. If the cost is not important, I recommend that you use this RAID structure for your databases. The following illustration shows how RAID 10 works.
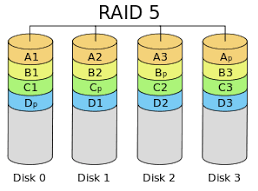
RAID 5:
It can be created with at least 3 disks. As with RAID 0, it spreads data evenly across disks. However, in case any of the disks fails, an algorithm called parity is written to the disks in order to restore the data in the corrupted disk in order to prevent data loss. In the picture below, you can see how data and parity in RAID 5 are written to disks.
If you configure RAID 5 using 3 disks, the system will be protected against 1 disk failure.
RAID 5 in terms of data security and performance:
In RAID 5, the read performance is very good and the write performance is poor. If you have a read rate of up to 80% in your system and your organization avoids disk cost, you can use RAID 5 for your databases.
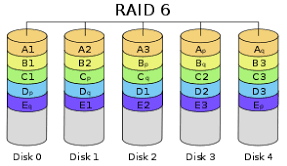
RAID 6:
RAID 6 is a bit more safer than RAID 5. Protected against loss of two disks. It can be created with at least 4 disks.
I usually prefer 6 + 2 or 8 + 2.
For example, if you create 3 + 2, it will divide the data into 3 and write 2 parity information as below.
The write speed of RAID 6 is slower than RAID 5. But it is a more safe RAID level against data loss. When you create it as 8 + 2, it will also divide the data into 8 equal parts, which means it is good in terms of performance.
Conclusion:
Considering the above RAID levels, you can decide which RAID structure you want for your application.
You should consider the IOPS that your applications need. I think it’s not necessary to double the cost unnecessarily by using the RAID 10 structure for an application with little write rate.
You can specify RAID levels according to the IOPS requirement of your applications.
Storage:
There are pool concept. In some storage the name of this concept is domain. You can define multiple disk in the same pool and then define drives to use from this pool on the server. You can create a pool by combining different types of disks. For example, you can create a pool by combining 10 SSDs, 20 SASs and 50 NearLine disks. As the number of disks increases, IOPS will increase.
By defining different pools for different applications, you can isolate application’s IO from others. Of course, it would be unreasonable to define different pools for all applications. If you define a different pool for each application, you will unnecessarily allocate IO capacity for unused applications.
For example, suppose we put 10 SSDs and 20 SAS disks in a pool. Every drive we define from this pool will share the amount of IOPS that these 30 disks can provide. If we create such a special pool for a database that is big and unused, the amount of IOPS of this pool will be wasted.
Pools should be created considering the IOPS requirement of applications. I recommend you read my article “How To Calculate IOPS and Throughput of Your Database Server Using Data Collector“.
Tiering: With Tiering, the most widely used spaces can be automatically transferred to the SSD and the less-used spaces can be transferred online and automatically to SAS or Nearline drives.
If your storage supports tiering, it will make your work very easy. Tiering collects statistics about the data access density and then moves the data in the background between the SSD-SAS-NEARLINE layers using these statistics.
You can determine in which timeframes you will collect statistics, and in which timeframes you will transfer the data between these layers. You can set a schedule to collect statistics during working hours and online transfer between the SSD-SAS-NEARLINE layers at night.
![]()