 Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux
Database Tutorials MSSQL, Oracle, PostgreSQL, MySQL, MariaDB, DB2, Sybase, Teradata, Big Data, NOSQL, MongoDB, Couchbase, Cassandra, Windows, Linux 
In this article, we will examine the join types in the execution plan.
Before you read this article, you can get more from this article if you read the articles named “What is Execution Plan On SQL Server” and “Join Types in SQL Server“.
SQL Server converts the JOIN expressions written in TSQL to the following join types in the background.
While performing this conversion, it will execute the query in the following join types, which will work better.
- NESTED LOOPS JOIN
- MERGE JOIN
- HASH JOIN
First we will explain the concepts above. We will then use the queries in the topic “Join Types in SQL Server” to create examples.
And we’ll add indexes to some columns to make the query work better.
After adding an index, we will see how the join process (nested loop, merge, hash) in the background changes.
NESTED LOOPS JOIN
Marks one of the tables as inner (inner) and the other as outer, and for each row of the table marked as outer, reads each row in the table marked inner.
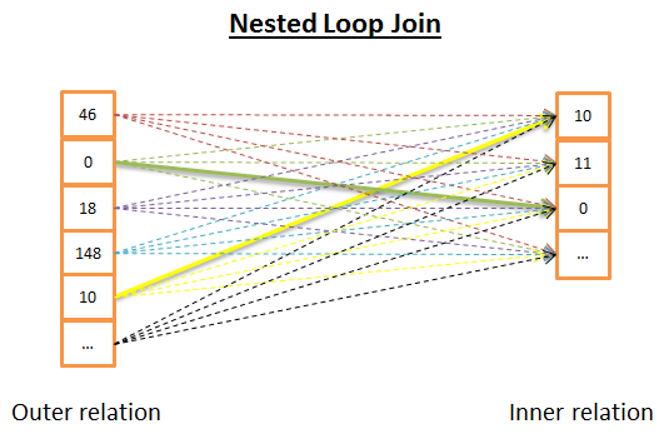
If one of the tables is small and the other is large and the large table has an index in the join column, then this join type will work very well. The following picture will be a good example for you to understand the logic of Nested Loop Join.
As you can see in the picture below, for each row of the table marked as outer on the left, all rows of the table marked as inner on the right side are checked.
If there is an index on the join column of the table marked as outer, it will work very well.
MERGE JOIN
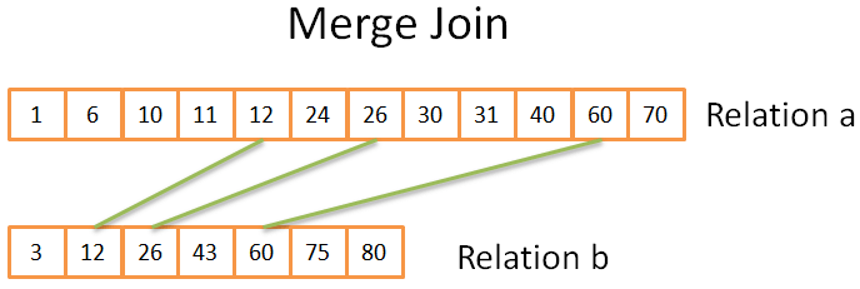
If the two tables to join are not small and the two tables are ordered according to the join columns (if there is an index in the join columns), merge join will be the most efficient option.
Let’s go through a sample,
Consider a join as follows.
1 | Select * from table1 INNER JOIN table2 ON table1.a = table2.b |
In column a in the first table there is an index in ordered structure,
In column b in the secondary table there is an index in ordered structure too.
As a result of such a join, merge join will work very well because both of the columns to be joined are in ordered structure.
Merge Join compares two columns in a join with these two columns, and if it is equal, it returns the result.
HASH JOIN
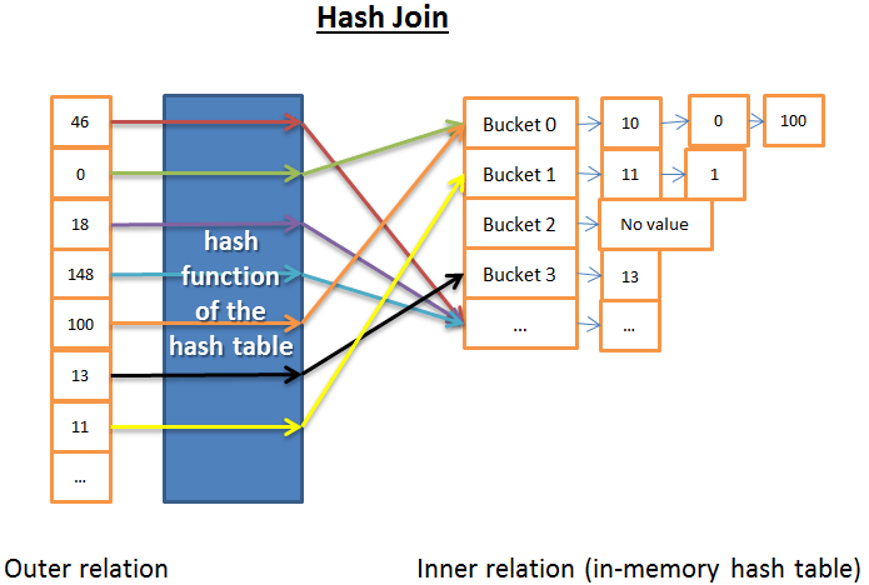
The type of join we do not like. We do not want to see in the execution plan.
If large, unordered, and non-indexed tables enter the join process, SQL Server will have to use the HASH JOIN method to join these two tables.
A hash table is created in the memory by taking the smallest of the two tables.
Then the large table is scanned and the hash value of the large table is compared to the hash value of the hash table in the memory, and equal values are added to the result list.
Below you can find the image showing the hash join.
Which of these join methods is more efficient?
Which join type should we try to convert to which join type?
When we told Hash join, we said we do not like this join type.
Let’s illustrate how we can convert a hash join to other join types. I will proceed using queries from my previous article, “Join Types in SQL Server“.
For example, let’s open a new query page and paste the INNER JOIN query.
1 2 | select s.CityName,my.FoodName from City s INNER JOIN FamousFood my ON s.ID=my.CityID |
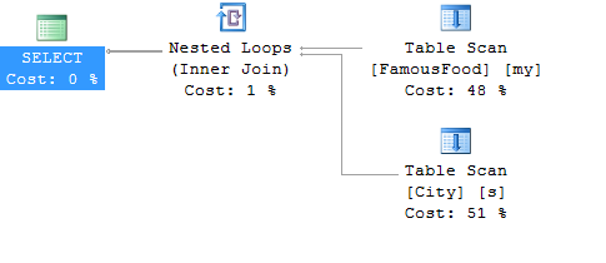
Next, let’s look at how to create the estimated execution plan without running the query by clicking on the Display Estimated Execution plan as shown in the picture below.
Since there are no indexes in both tables, Table Scan has performed on both tables, and Hash Join has performed afterwards.
Let’s run the same script again by adding an index to the join column. For example, add the index to the CityID column in the FamousFood table using the following script.
1 2 3 4 5 6 7 8 | USE [Test] GO CREATE NONCLUSTERED INDEX [IX_CityID] ON [dbo].[FamousFood] ( [CityID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO |
After adding our index, let’s look at the estimated execution plan just as we did before.
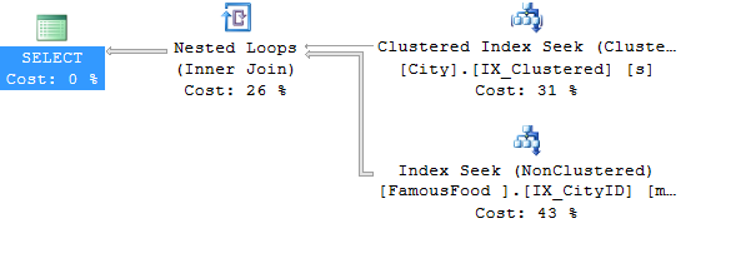
We always read the execution plan starting from the right side. When we look at the following execution plan;
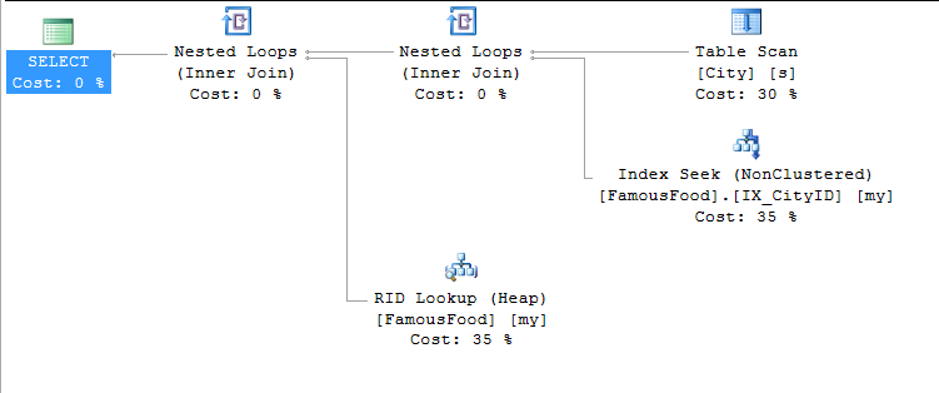
First, in the FamousFood table we have index seek from the index named IX_CityID (It goes to the index and finds records that it searched for without searching all of the index)
Later, it made a table scan (It goes to the index and finds records that it searched for with scanning all of the index) from the City table and concatenated the two results with Nested Loop method,
Since there is no Clustered Index in the FamousFood table,Sql server uses row id from index named IX_CityID to do RID Lookup and brings the other columns from the table.
Finally, the results from the previous join and RID Lookup are combined with the Nested Loops join type to produce the result.
What is RID Lookup ?,
What is Clustered Index?,
What are the differences between Clustered and NonClustered Indexes?
The answers to your questions can be found in the following articles.
“Index Concept and Performance Effect on SQL Server“,
“Statistics Concept and Performance Effect on SQL Server“,(Scan, seek operations have been examined in detail in this article.)
“Difference Between Clustered Index and Non Clustered Index”
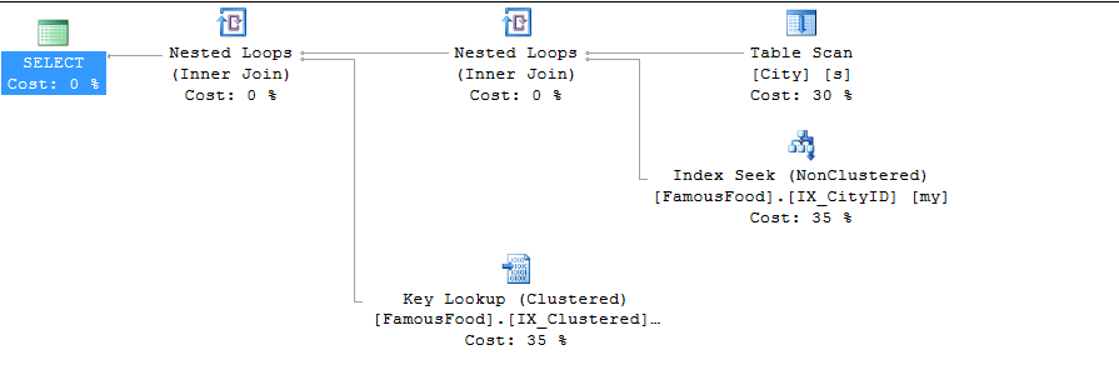
Let’s put a Clustered Index on the FamousFood table with the following script and then look at the execution plan again.
1 2 3 4 5 6 7 8 | USE [Test] GO CREATE UNIQUE CLUSTERED INDEX [IX_Clustered] ON [dbo].[FamousFood] ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO |
Looking back at the execution plan, Key Lookup came in instead of RID Lookup as follows.
You can find the RID Lookup and Key Lookup difference in the article “Difference Between Clustered Index and Non Clustered Index“.
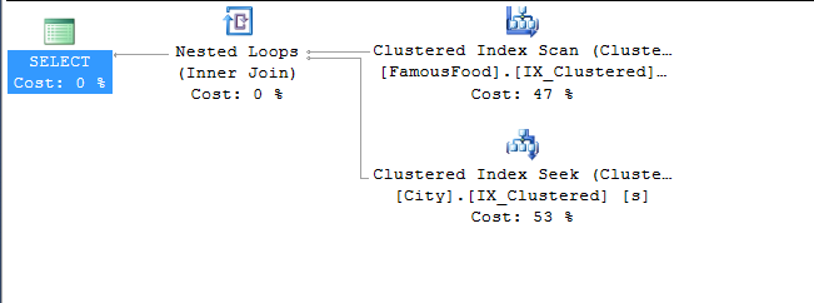
Let’s keep improving our query. To remove the TableScan for the Cities table, let’s put an index into the ID column that joins the Cities table.
I would prefer to place the Clustered Index in this example because the ID column is the determinative column for the Cities table.
1 2 3 4 5 6 7 8 | USE [Test] GO CREATE UNIQUE CLUSTERED INDEX [IX_Clustered] ON [dbo].[City] ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO |
let’s look at the execution plan again.
As you can see below, the table scan for the City table returned to the Clustered Index seek.
SQL Server was performing Index Seek + Key Lookup in a previous execution plan.
As you remember the previous execution plan, the sql server first performs index seek, then join, then key lookup, and then join again.
Instead, it decided that the cost of the Clustered Index Scan + single join process was less.
Of course, the number of columns in the table, the size of the data can change the sql server’s decision.
As you see in our query, the CityID column of the FamousFood table is joined and the FoodName column of the FamousFood table is also selected in the select section.
We can use the following script to add the FoodName column to the included field of the IX_CityID index that we created, so that we can use the IX_CityID index instead of the Clustered Index Scan.
1 2 3 4 5 6 7 8 9 10 11 | USE [Test] GO SET ANSI_PADDING ON GO CREATE NONCLUSTERED INDEX [IX_CityID] ON [dbo].[FamousFood] ( [CityID] ASC ) INCLUDE ([FoodName]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO |
After running the script, I see that the clustered index scan process is still on the execution plan.
Let’s add a few columns to the FamousFood table and fill these columns with meaningless values.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | Use Test GO BEGIN TRANSACTION SET QUOTED_IDENTIFIER ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF SET CONCAT_NULL_YIELDS_NULL ON SET ANSI_NULLS ON SET ANSI_PADDING ON SET ANSI_WARNINGS ON COMMIT BEGIN TRANSACTION GO ALTER TABLE dbo.FamousFood ADD test nchar(10) NULL, test2 nchar(10) NULL, test3 nchar(10) NULL, test4 nchar(10) NULL, test5 nchar(10) NULL GO ALTER TABLE dbo.FamousFood SET (LOCK_ESCALATION = TABLE) GO COMMIT USE [Test] GO UPDATE [dbo].[FamousFood] SET [test] = '0123456789' ,[test2] = '0123456789' ,[test3] = '0123456789' ,[test4] = '0123456789' ,[test5] = '0123456789' GO |
Then we will insert the table to enlarge the table.
Let’s run the following script to set the value of the ID column to auto-increment before doing the Insert operation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | BEGIN TRANSACTION SET QUOTED_IDENTIFIER ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF SET CONCAT_NULL_YIELDS_NULL ON SET ANSI_NULLS ON SET ANSI_PADDING ON SET ANSI_WARNINGS ON COMMIT BEGIN TRANSACTION GO CREATE TABLE dbo.Tmp_FamousFood ( ID int NOT NULL IDENTITY (1, 1), CityID int NULL, FoodName varchar(100) NULL, test nchar(10) NULL, test2 nchar(10) NULL, test3 nchar(10) NULL, test4 nchar(10) NULL, test5 nchar(10) NULL ) ON [PRIMARY] GO ALTER TABLE dbo.Tmp_FamousFood SET (LOCK_ESCALATION = TABLE) GO SET IDENTITY_INSERT dbo.Tmp_FamousFood ON GO IF EXISTS(SELECT * FROM dbo.FamousFood ) EXEC('INSERT INTO dbo.Tmp_FamousFood (ID, CityID, FoodName, test, test2, test3, test4, test5) SELECT ID, CityID, FoodName, test, test2, test3, test4, test5 FROM dbo.FamousFood WITH (HOLDLOCK TABLOCKX)') GO SET IDENTITY_INSERT dbo.Tmp_FamousFood OFF GO DROP TABLE dbo.FamousFood GO EXECUTE sp_rename N'dbo.Tmp_FamousFood ', N'FamousFood ', 'OBJECT' GO CREATE UNIQUE CLUSTERED INDEX IX_Clustered ON dbo.FamousFood ( ID ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX IX_CityID ON dbo.FamousFood ( CityID ) INCLUDE (FoodName) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO COMMIT |
Then we will I add records to our table using the following script. You can run the script for 1 minute.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | USE [Test] GO while(1=1) BEGIN INSERT INTO [dbo].[FamousFood] ([CityID] ,[FoodName] ,[test] ,[test2] ,[test3] ,[test4] ,[test5]) VALUES (1 ,'Test' ,'0123456789' ,'0123456789' ,'0123456789' ,'0123456789' ,'0123456789') END |
Once we stop the script, let’s look at the execution plan again.
As you can see, I only increased the number of columns and the number of records in the FamousFood table (setting the ID to automatically increase does not affect the execution plan)
SQL Server did not choose to use the nonclustered index we created in the FamousFood table when the number of rows (data density) in the table was low.
Since the table is small, it has been estimated that it would be less costly to bring the data over the clustered index.
But once the data in the table grows, it chose to use the index to cover our query (an index that contains the columns of the select and where expressions).
Another point that attracts our attention is Merge Join.
It did not use merge join before.
Because it was using the clustered index instead of the nonclustered index in the FamousFoods table when doing the join process.
When we look at the execution plan below;
ClusteredIndexScan was made using the index named IX_Clustered of the City table. IX_Clustered index has an ID column.
IndexScan has been made using the index names IX_CityID of the FamousFood Table. IX_CityID index has an CityID column.
While the table was small, the ID column of the City table was joined with the ID column of the FamousFood table.
When the table grows, it performs merge join on the ordered columns (with index).
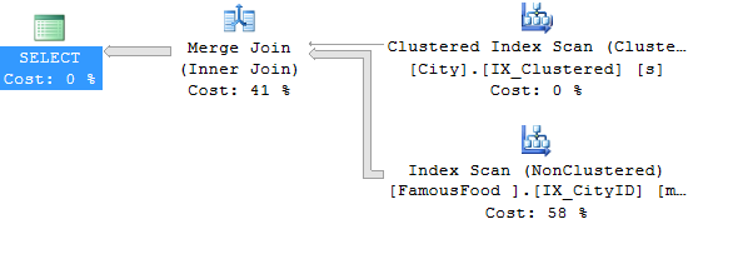
As you can see, there can be hash join, nested loop or merge join on the same query, based on index and number of records in the table.
Why does SQL Server perform Index Scan and Clustered Index Scan?
Can we convert these operations to Clustered Index Seek and Index Seek?
Because the result set of the join process is getting almost all the rows.
By filtering the query as follows, the execution plan will return to index seek and clustered index seek.
1 2 3 | select s.CityName,my.FoodName from City s INNER JOIN FamousFood my ON s.ID=my.CityID where my.CityID=42 |
In the article “Spool Concept in Execution Plan(Eager Spool, Lazy Spool)” we will continue to enter the details of the execution plan.
You can reach our articles by searching for words that contain the subject you are interested.
What are the differences between Index Scan and Index Seek?
What are the differences between RID Lookup and KeyLookup?
The answers to these questions can be found in the article titled “Statistics Concept and Performance Effect on SQL Server“.
![]()